【3D生成AI】Hunyuan3D-2-WinPortableを使ってみた

どうもこんにちは、クララです。
2025年秋以降、AIブームによる需要増加によってメモリ・SSD・グラボ等のPCパーツの価格が高騰していますね。
なかなか下がらないメモリ価格をネット・店頭で見るたびに自作PC愛好家としては陰鬱な気分になります😅
ですが、裏を返せばAIが発展を遂げているとも捉えられるので、時代の流れにうまく乗っていけたらと思い、3DCGモデルや映像制作ができるAIソフトを試してみることにしました。
今回は、クラウドAIサービスを使用せず手持ちのPC上で動作するローカル3D生成AI「Hunyuan3D-2-WinPortable」を使って、キャラクターイラストから3Dモデルを作成してみました。
ローカルAIは設定がやや面倒ですが、実際のやり方や自分がつまづいたポイント・解決方法をまとめました。
また、Hunyuan 3D-2を使って3Dモデルを作成する方法や作成例についても紹介します。
ご意見・質問等はクララのTwitter(https://twitter.com/klala_lab)まで(^^)/
広告/AD
3D生成AIについて
まず3D生成AIとは何か、生成AI(Google Gemini)に聞いてみました。
3D生成AIは、テキスト(文字)や2D画像から、自動的に立体的な3Dモデルを生成する技術です。
専門的な知識や数時間かかる手作業のモデリングを、短時間で自動化し、ゲーム、VR、メタバース、3Dプリンティング向けにデータを作成できるため、誰でも簡単に3Dコンテンツ制作が可能になります。
だそうです。
以下は「Hunyuan3D-2.1」を使って、2Dイラストから作成した3Dモデル(3DCGソフト「Blender」上で表示)の例です。
本ブログでもBlenderのモデリング手法については過去記事でいろいろと紹介してきましたが、モデリング技術を習得するのには時間が必要ですし、複雑な人物の3DCGモデルを手作業でモデリングしたりテクスチャ作成したりするのにも時間がかかります。
ですが、3D生成AIを使えばたった数十秒~数分でイラストから3Dモデルができてしまいます。
(BlendAI株式会社のキャラクター「デルタもん」のイラストをAIへのインプットとして使用しました。)

まだまだ3Dモデルのクオリティ的には未熟で、ところどころ形状が破綻していたりテクスチャがおかしかったりと最終的には人の手による手直しが必要になりますが、作品作りの下地や、背景に大量に配置するオブジェクトの作成など、さまざまな形で3DCGに活用できそうです。
クラウドAIとローカルAIの違い

AIは、演算処理を行う場所によってクラウドとローカルの2種類に大きく分けられます。
- クラウドAI:インターネット経由で外部サーバーのAIを使う
- ローカルAI:自分のPC(ローカル環境)でAIを使う
クラウドAIは、サービスを提供する企業のサーバー上でAI演算を行うため、ユーザーは高性能なPCを購入したり、AIを動かすための環境構築を行わなくてもAIを使うことができます。
また、なかなか個人のPCで動かすのが難しい巨大なAIモデルを使えるため、基本的にローカルAIよりも高性能です。
ただし、サービスを利用する代わりにサブスクリプション(定額課金)あるいはクレジット(従量課金)を支払うのが前提なので、無料で作成できる回数や機能に制限があります。
ローカルAIは初期費用(PC購入)が高額かつ環境構築に手間がかかりますが、AIを自由にカスタマイズして好きなだけ使うことができます。
ただし、クラウドAIと比べて利用できるサービスの選択肢が少なかったり、(課金クラウドAIと比べて)生成されるモデルのクオリティが低いなど、あまり商用用途には向いていないと思います(あくまでも個人の見解ですが)。
とはいえ、既にゲームや3DCG用にPCを持っている方にとっては手持ちのリソースをそのまま流用する形で無料でAIを使えるので、一度ローカルAIを試してみる価値はあるのではないでしょうか。
ローカルAI利用に必要なPCスペック

ローカルAIを快適に利用するためには、「ビデオカード(グラフィックボード、GPU)」「メインメモリ(メモリ)」「SSD」の性能・容量が重要です。
AI演算を行うビデオカードについてですが、AIは計算を行う際に大量のデータ置き場(=メモリ)容量を必要とするため、GPUの性能だけでなく、VRAM容量が重要です。最低でも12GB, できれば16GB以上のGPUを用意しておきたいです。
また、AIツールで使用されているフレームワーク(Pytorch)がNVIDIA製GPUに最適化されているため、Nvidia製GPU(特にRTXシリーズ)を使用するのがおすすめです。
さらに、AI計算を行う際にモデルのロード・バッファやVRAM容量の補完を担うメインメモリ(メモリ)についても32GB以上がおすすめです。
ちなみに、今回の記事で紹介するローカルAI「Hunyuan3D-2-WinPortable」を動作させるためのPCスペック基本要件は以下の通りです。
- Nvidia製ビデオカード(GPU)- ドライバーバージョン576.57以降に対応のもの
- VRAM容量 3GB以上(ジオメトリ生成のみ行う場合)
- VRAM容量 6GB以上(ジオメトリ生成+テクスチャ生成を行う場合)
- メインメモリ容量24GB以上
(参照元:https://github.com/YanWenKun/Hunyuan3D-2-WinPortable)
さらに、AIを使用するためには数10GB程度のモデルデータをインストールする必要があるため、最低でも500GB、できれば1TB以上のSSDが必要です。
3D生成AIの推奨PCスペックをまとめると以下のようになります。
- VRAM容量16GB以上のNvidia製ビデオカード(GPU)– RTX5060Ti(16GB), RTX5070Ti, RTX5080など
- メインメモリ容量32GB以上
- SSD容量 1TB以上
昨年(2025年)、3DCG制作用に32GBメモリ・RTX5060Ti搭載のPCを自作しました。
部品の選び方や、実際の組み立て方法について記事にまとめましたので、興味がある方はあわせて参照してください。
広告/AD
Hunyuan3D-2-WinPortableの紹介
こちらの項目では、ローカル3D生成AI「Hunyuan3D-2-WinPortable」とそのインストール方法について紹介していきます。
また、インストール時の注意点や発生しやすいエラー・対処法についてもまとめます。
Hunyuan3Dについて
Hunyuan3D(混元3D)とは、中国のTencent社が開発したAIモデルです。
画像あるいは命令文(プロンプト)を入力することで、3Dモデルを生成することができます。
2024年に発表された後毎年バージョンアップが行われ、2026年現在クラウドAIとしてはバージョン3.0が最新バージョンとなっています。
一方で、以前のバージョンはオープンソースとしてGitHubで公開されており(以下リンク参照)それをもとに有志の方がAIモデルを組み込んだアプリケーション等の形で公開しています。
https://github.com/Tencent-Hunyuan/Hunyuan3D-2
Hunyuan3D-2-WinPortableについて
Hunyuan3D-2-Winportableは、YanWenKun氏がGithub上で公開している、Hunyuan3D-2をWindows環境で実行するためのアプリケーションです。
以下のリンク先からダウンロードできます。
https://github.com/YanWenKun/Hunyuan3D-2-WinPortable
使用環境によってダウンロードするファイルが異なるため、次の項目で詳しい手順を説明します。
インストール方法(RTX5060Tiの場合)
YanWenKun氏のGithubページに記載のとおり、使用するGPUによって対応するCuda Toolkitのバージョンとダウンロードするファイルが異なります。
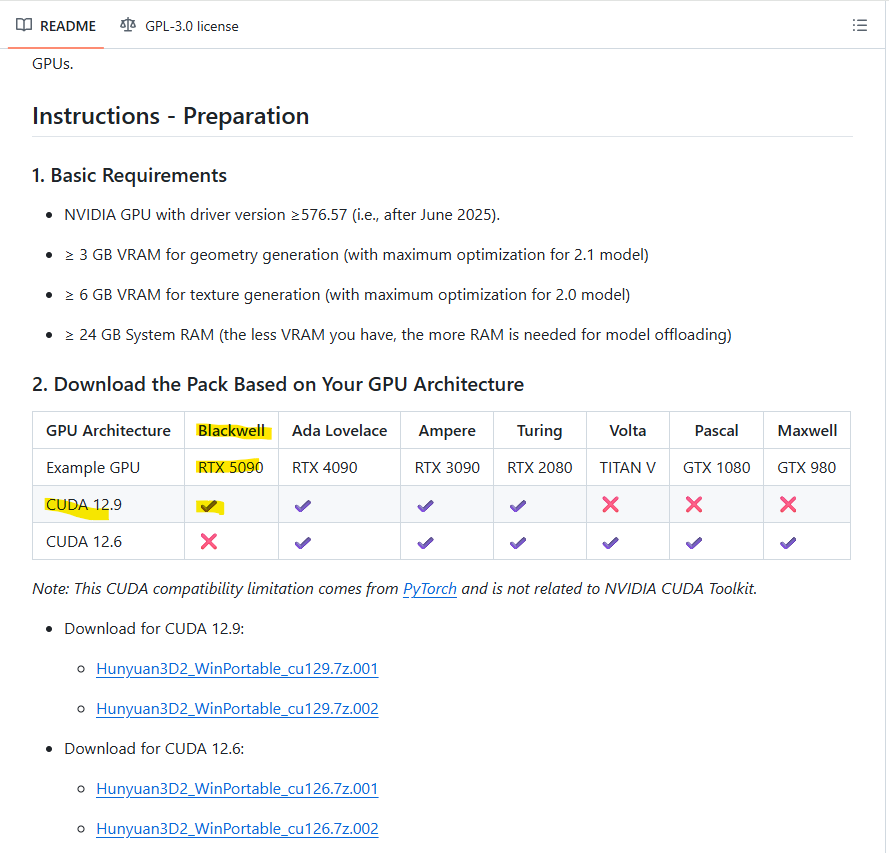
ここでは、RTX5060Tiの場合のインストール手順を例として紹介します。
1.Cuda Toolkitのインストール
RTX5000番台(Blackwell)のGPUを使用する場合はCuda Toolkit バージョン12.9をインストールする必要があります。
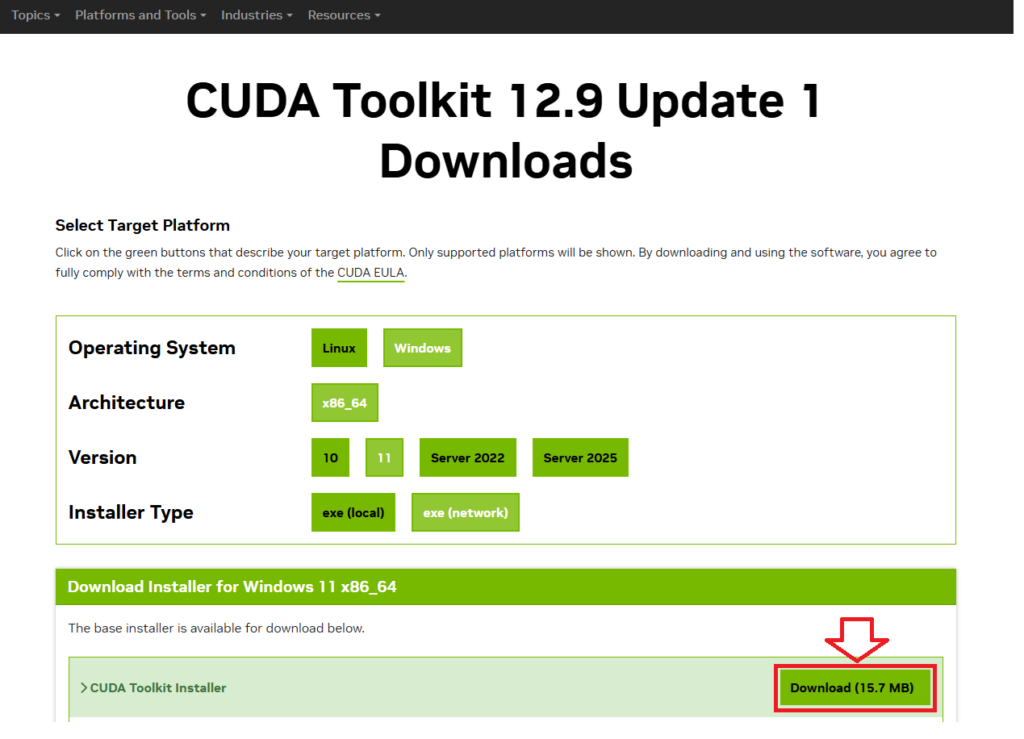
CUDA Toolkit 12.9はこちらのリンク先からインストーラをダウンロードできます。
OSを選択し「Download」をクリックするとインストーラのダウンロードが始まります。
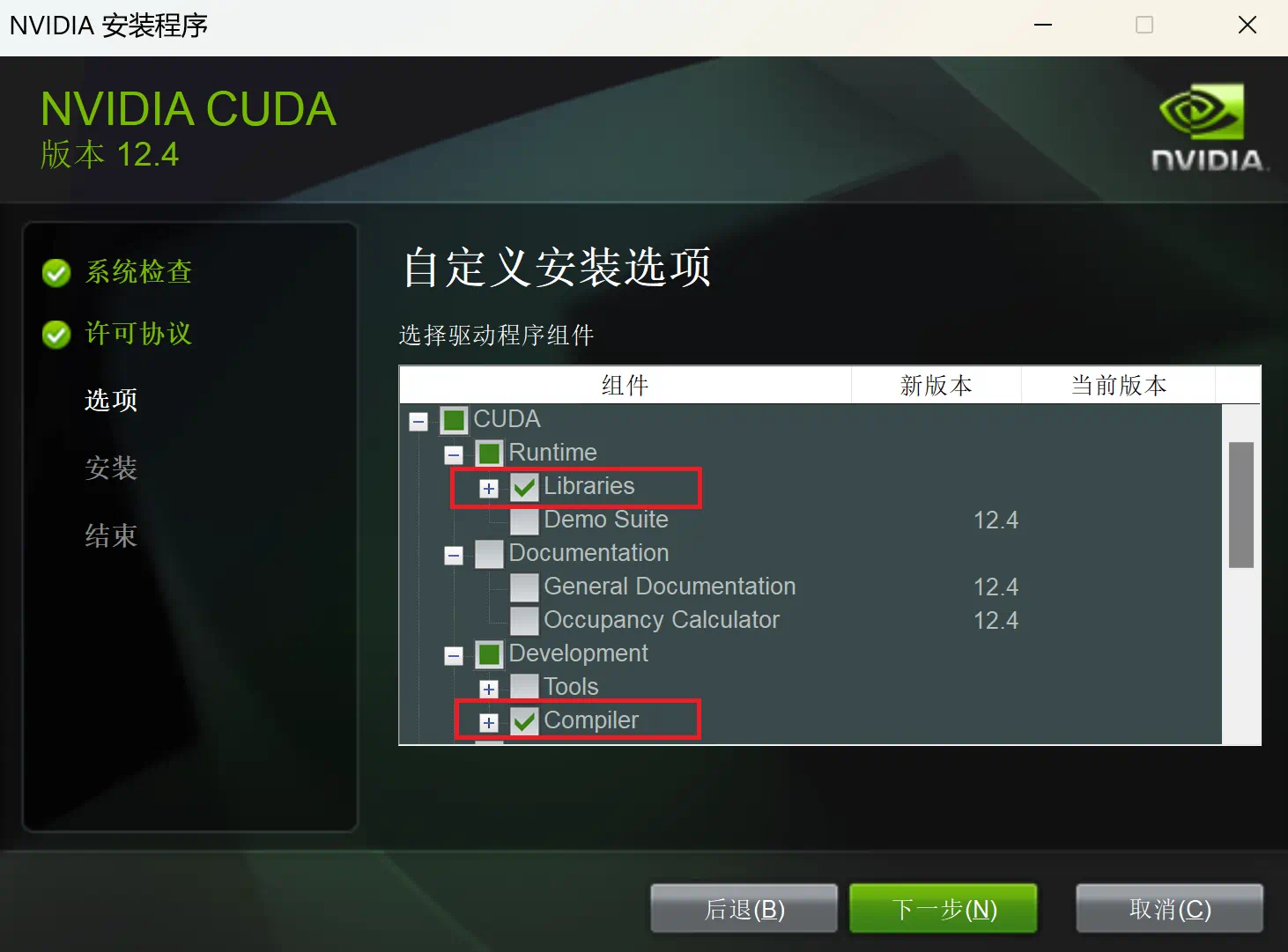
(Githubの説明によると、インストールの際は「カスタム」を選択してライブラリーとコンパイラーを選択すればよいそうですが、私はすべてインストールしました。)
{kind=link}
2.Visual Studio Build Tools 2022のインストール
Windowsを使用する場合、アプリケーションをビルドするのにVisual Studio Build Toolsが必要です。
現在の最新バージョンは2026ですが、こちらのリンク先からVisual Studio Build Tools 2022をインストールしました(Microsoftのアカウントでのログインを求められるので注意)。
https://visualstudio.microsoft.com/ja/vs/older-downloads
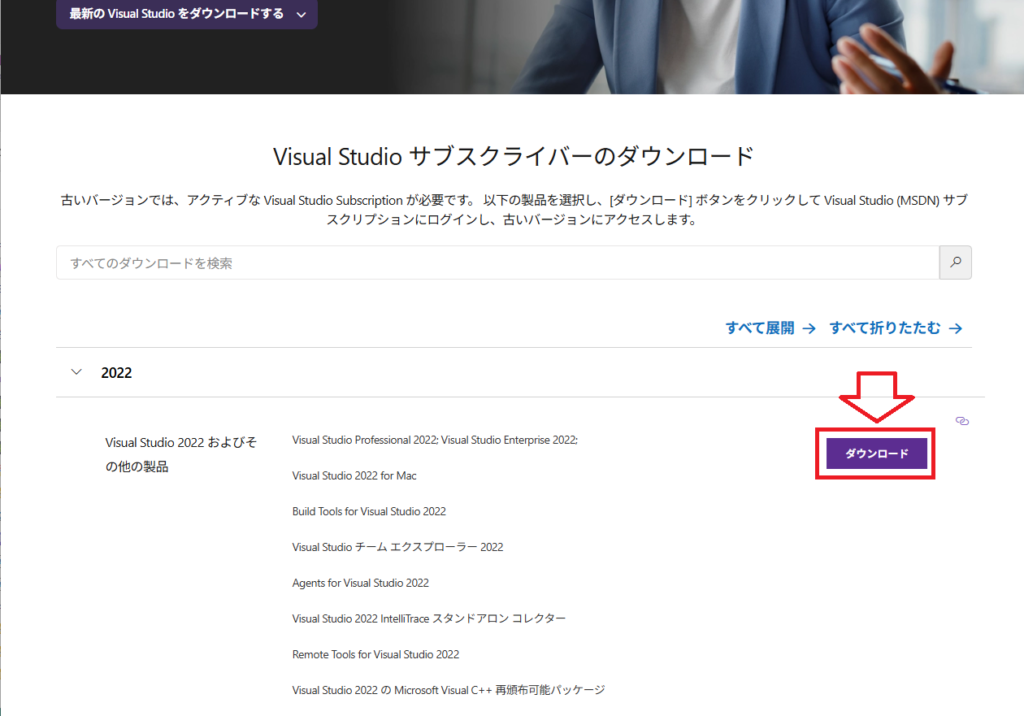
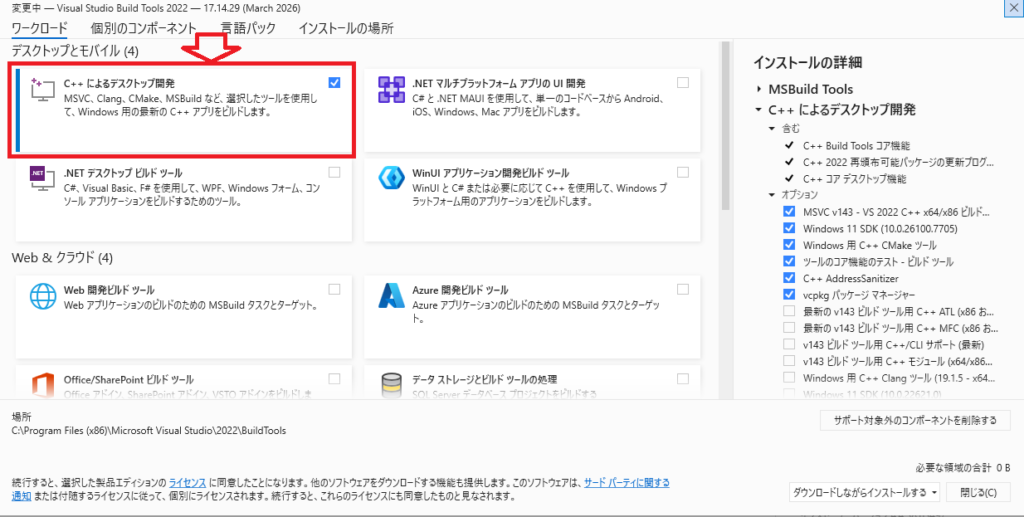
「C++によるデスクトップ開発」にチェックを入れて、以下をインストールします。
- MSVC v143
- Windows 10/11 SDK
3.Zipファイルのダウンロード・解凍
Githubの説明に従い、以下の2つのファイルをダウンロードします(RTX5000系・Cuda Toolkit 12.9に対応)
Hunyuan3D2_WinPortable_cu129.7z.001
Hunyuan3D2_WinPortable_cu129.7z.002
2つのファイルを同じフォルダにおいて、「7z.001」の方を解凍すると「7z.001」「7z.002」の2つのファイルを参照して解凍が行われます(7-zip等の圧縮・解凍ソフトを利用してください)。
解凍を行うフォルダのパスが長いとエラーが発生するため、「C:\AI\HY3D2」など短いフォルダ名を使用してください。
4.バッチファイルの実行
解凍が完了すると、以下のようなフォルダ構成になります。
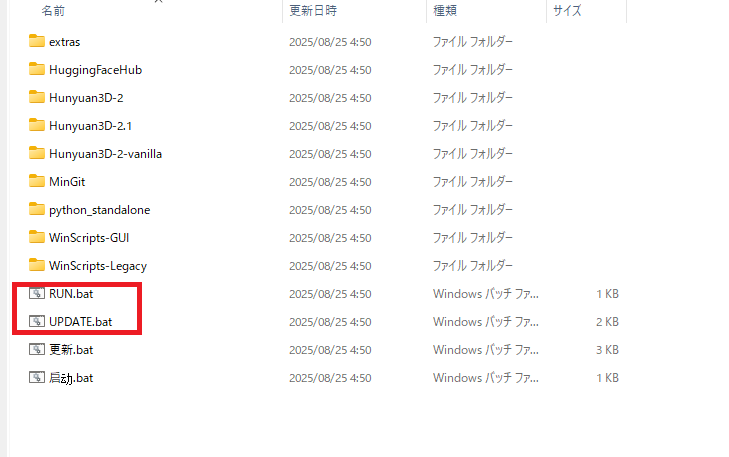
「RUN.bat」と「UPDATE.bat」の2つのファイルがありますが、それぞれ「起動用バッチファイル」「更新用バッチファイル」になります。
まずは「UPDATE.bat」をダブルクリックすることで、Hunyuan3Dに更新があるか確認します。
「RUN.bat」をダブルクリックすると、コマンドプロンプトの画面が立ち上がった後に「Hunyuan 3D 2 Series Launcher」の画面が立ち上がります。
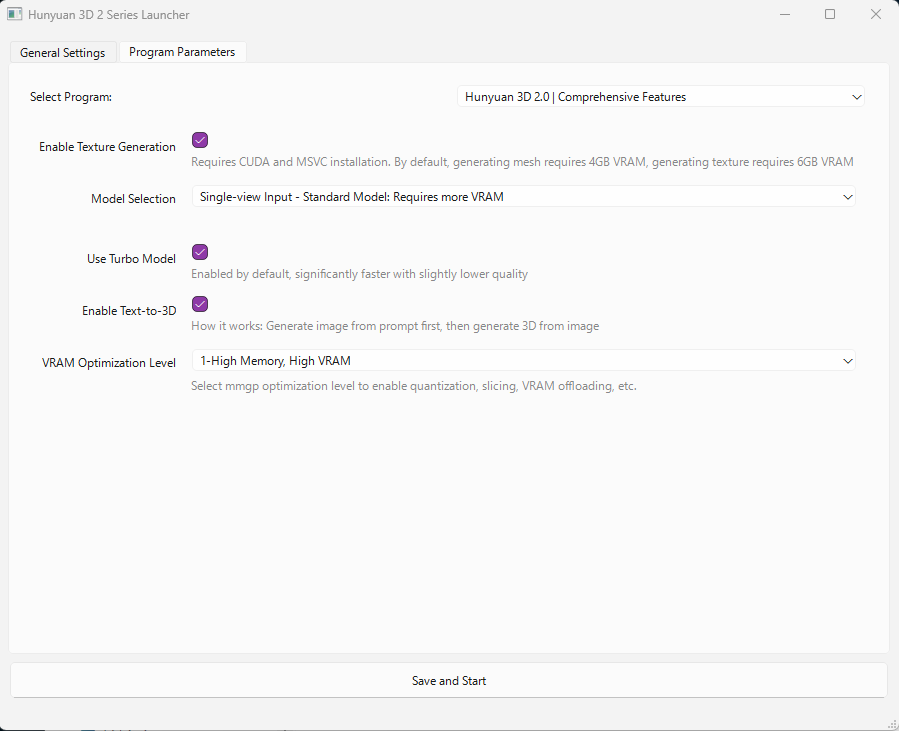
Launcherの「General Settings」のタブには何も入力しなくて大丈夫です。
「Program Parameters」のタブをクリックすると、以下のような画面が出ます。
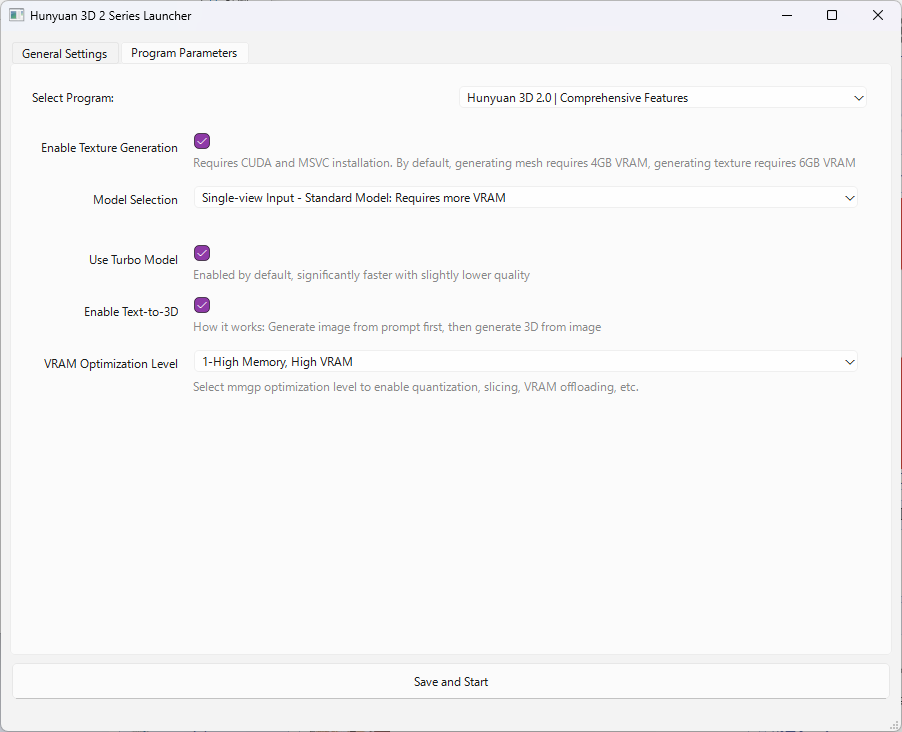
この画面の内容は後ほど説明しますが、ひとまず画面下部の「Save and Start」をクリックしてみます。
すると、以下のようなコマンドプロンプトのような画面に遷移します。
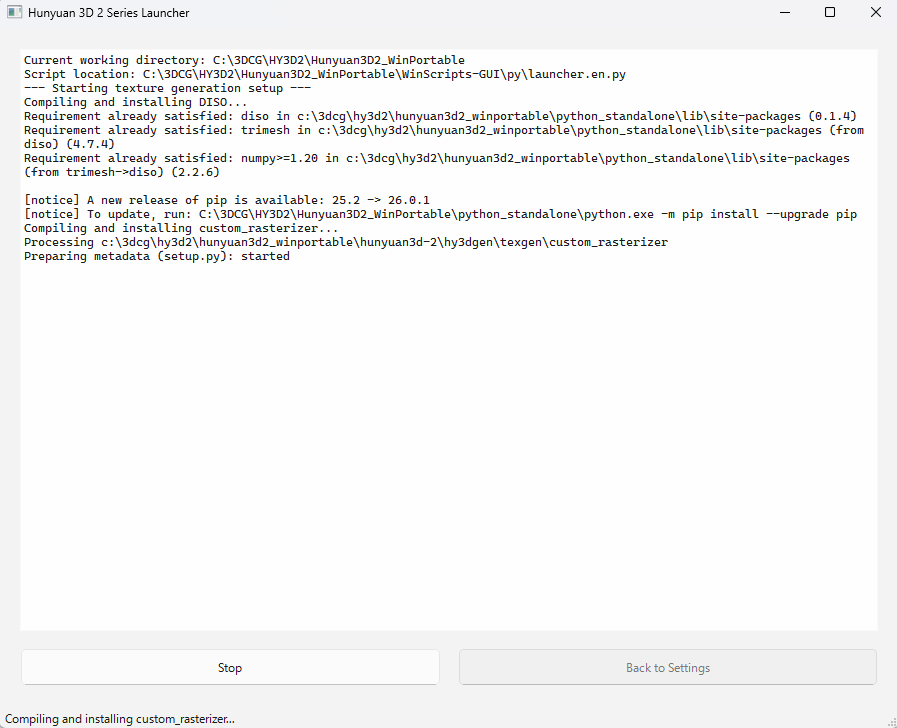
“ModuleNotFoundError: No module named 'triton'"というエラーメッセージが表示されますが、Hunyuan3Dの起動には影響ないため無視します。
以下のようなメッセージが表示されたら、GUIの準備ができた合図になります。
INFO: Started server process [34188]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)ブラウザを立ち上げて、"http://localhost:8080/“にアクセスすると以下のようにブラウザ上にHunyuan 3D-2のGUIが表示されます。
ここまで出来たら、ひとまずHunyuan3D-2-Winportableの起動は完了です。
インストール時の注意点・エラーについて
インストール時の注意点は以下のとおりです。
- Nvidia製のGPUを使用する
- GPUのドライバーを最新にする
- GPUのバージョンと整合したCUDA Toolkitをインストールする
- Visual Studio Build Tools 2022「MSVC v143」「Windows 10/11 SDK」をインストールする
- 環境変数の設定・確認を行う(設定後の再起動も)
- エラーの内容によってはcustom_rasterizerの再ビルドやPytorchの更新が必要
主なエラーとその対処方法を以下に紹介します。
(ちなみに、今どきはエラーの内容をChat GPTなどの生成AIに入力すると原因や対処方法のアドバイスをくれるので、困ったときの対処としておすすめです。)
custom_rasterizer(テクスチャ用CUDA拡張)が壊れている
私がHunyuan3D2を最初に実行しようとしたときに、メッシュ生成はできましたがテクスチャ生成を有効にしようとしたときにエラーが出てしまいました。
原因を確認したところ、テクスチャ生成は内部で”hy3dgen/texgen/custom_rasterizer”というCUDA拡張をビルドして使いますが、そのビルドが失敗し壊れていることが原因だとわかりました。
以下コマンドを実行することで、custom_rasterizerを手動ビルドすることができます。
C:\(Hunyuan3Dインストールフォルダ)\Hunyuan3D2_WinPortable\Hunyuan3D-2\hy3dgen\texgen\custom_rasterizer>C:\(Hunyuan3Dインストールフォルダ)\Hunyuan3D2_WinPortable\python_standalone/python.exe -m pip install .CUDA Toolkit/Visual Studio Build Toolsが入っていない・バージョン不整合
環境構築に必要なCUDA ToolkitとVisual Studio Build Toolsの適切なバージョンがインストールされていないとエラーが発生します。
以下はRTX5000系の例です。
- CUDA Toolkit: バージョン12.9
- Visual Studio Build Tools 2022
- MSVC v143
- Windows 10/11 SDK
コマンドプロンプトで以下を入力することで、CUDA Toolkitのバージョンを確認できます。
nvcc --version以下のような内容が出力されます。バージョン12.9であれば問題ありません。
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2025 NVIDIA Corporation
Built on Tue_May_27_02:24:01_Pacific_Daylight_Time_2025
Cuda compilation tools, release 12.9, V12.9.86
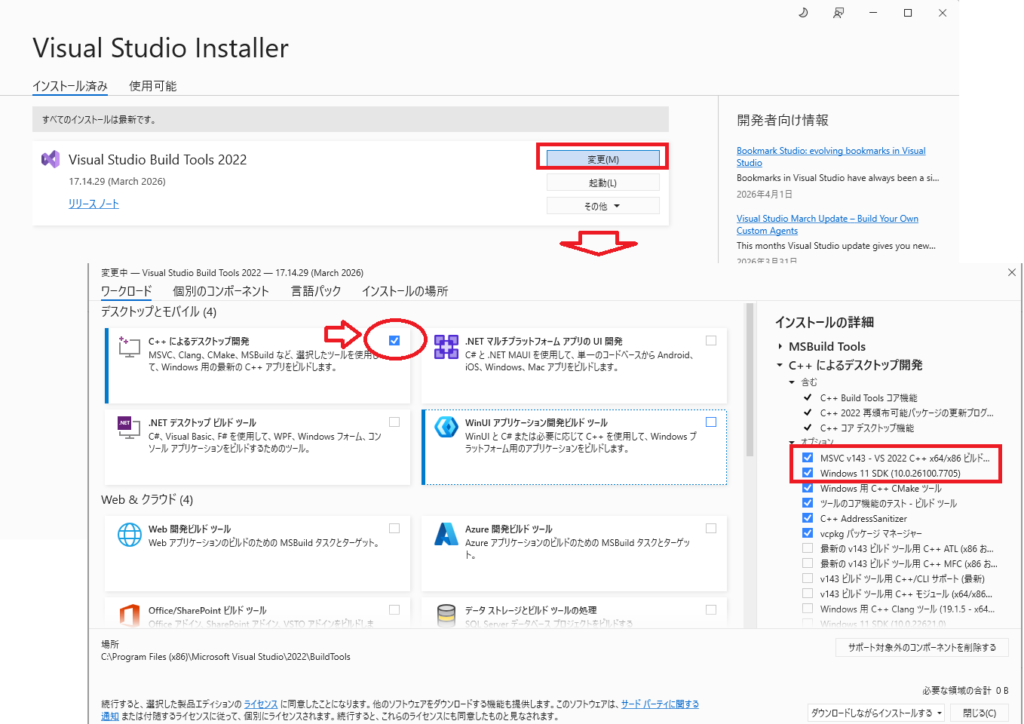
Build cuda_12.9.r12.9/compiler.36037853_0Visual Studio Build Toolsのバージョンは、Windowsのスタートメニューから「Visual Studio Installer」を起動することで、インストールされているBuild Toolsのバージョンを確認できます。
「C++によるデスクトップ開発」にチェックが入っていれば、「MSVC v143」「Windows 10/11 SDK」の2つはインストールされているため問題ありません。
Pytorchのバージョン不整合
RTX5000番台の場合、パッケージに同梱されているPythonのフレームワークであるpytorchがCuda Toolkit 12.9と整合していないためにエラーが出てしまう可能性があります。
コマンドプロンプト上で、Hunyuan3D portableに同梱されているpythonを-m pipコマンドを添えて実行し、以下コマンドを入力し、PyTorchを「Nightly(最新)」にしました。
C:\(Hunyuan3Dインストールフォルダ)\Hunyuan3D2_WinPortable\python_standalone\python.exe -m pip uninstall torch torchvision torchaudio
C:\(Hunyuan3Dインストールフォルダ)\Hunyuan3D2_WinPortable\python_standalone\python.exe -m pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu129関数"torch"をインポートし、PytorchのバージョンとCuda Toolkitのバージョン(RTX5000系の場合12.9がおすすめ)が整合しているかどうかを確認します。
C:\(Hunyuan3Dインストールフォルダ)\Hunyuan3D2_WinPortable\python_standalone>python.exe
Python 3.12.11 (main, Aug 18 2025, 19:17:54) [MSC v.1944 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch<br>>>> print(torch.__version__)
2.8.0+cu129
>>> print(torch.cuda.is_available())<br>True環境変数PATH
PyTorchのCUDA拡張ビルド時に以下のようなエラーが発生することがあります。
UserWarning:
It seems that the VC environment is activated but DISTUTILS_USE_SDK is not set.このような場合は、環境変数が不完全なので、コマンドプロンプトを管理者権限で起動の上で、以下のようなコマンドを打って環境変数を書き換える必要があります。
set DISTUTILS_USE_SDK=1
set CUDA_HOME=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.9
set CUDA_PATH=C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.9以下コマンドを打って、上記のPATHが出力されればOKです。
echo %CUDA_HOME%
echo %CUDA_PATH%広告/AD
Hunyuan3Dを実際に使ってみよう
ここからは、Hunyuan3Dの使い方や出力結果について、設定画面や生成した3Dモデル画像を交えながら紹介していきます。
使用環境は以下のとおりです。
- Windows 11
- CPU Intel Core Ultra 7 265KF
- メモリ32GB(DDR5-6000)
- GPU RTX5060Ti(VRAM 16GB)
もう一度起動方法のおさらいをしておきましょう。
まずは”RUN.bat”をダブルクリックしてLauncherを立ち上げます。
画面下部の「Save and Start」をクリックし、”Uvicorn running on http://0.0.0.0:8080”が表示された後、
ブラウザーから"http://localhost:8080/“にアクセスするとHunyuan3D-2が起動します。
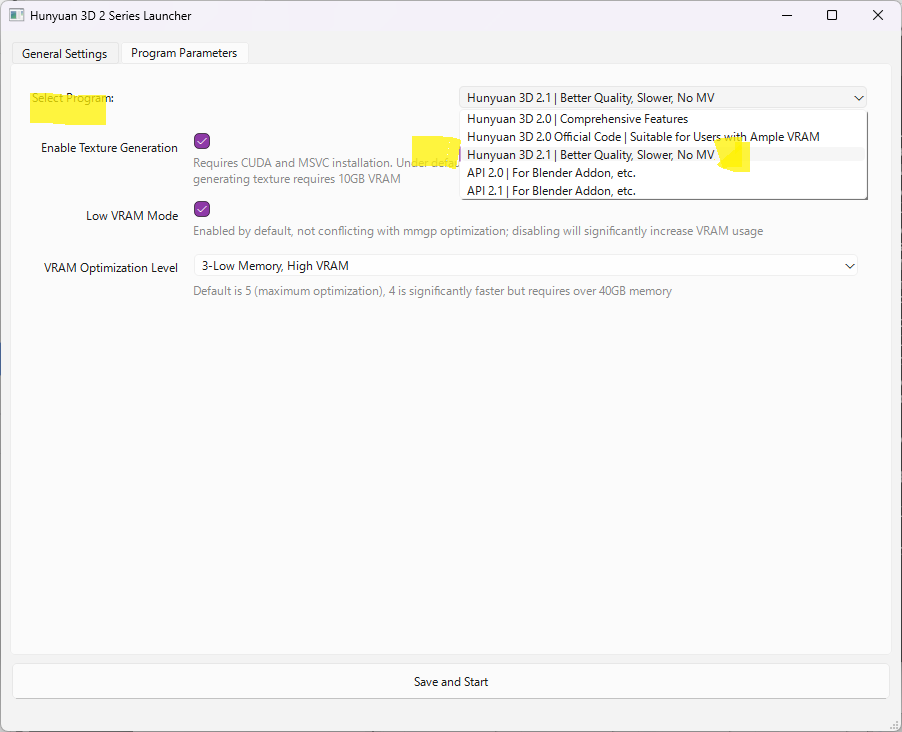
プログラムの選択について
Launcherの右上から、実行するプログラムを選択することができます。
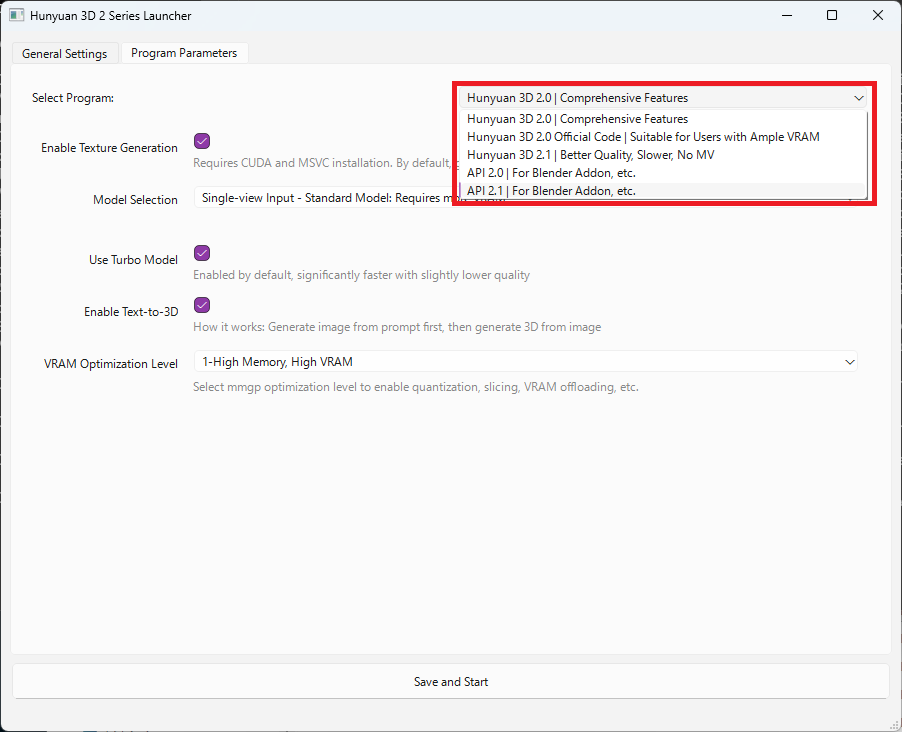
以下の5種類のプログラムを選択できます。
- Hunyuan3D 2.0 |Comprehensive Features : テキスト生成、MV(Multi View: 複数画像から生成)に対応した包括機能版。
- Hunyuan3D 2.0 Official Code:大容量のVRAMを必要とする高解像度版
- Hunyuan3D 2.1 : 2.0より新しいバージョン。生成モデルのクオリティが高くPBR(物理ベースレンダリング)マテリアルに対応するが、2.0と比べて生成時間が長い。
- API 2.0/2.1 : Blenderなどの外部アプリケーションからAPIサーバーとして利用するモード
使用するインプットや作りたい生成物によって、1番目のHunyuan3D 2.0と3番目の2.1のどちらかを選択するのがおすすめです。
実際にHunyuan 3D 2.0と2.1でそれぞれで3D生成をしてみて、両者の違いをお見せしたいと思います。
Hunyuan3D-2.0
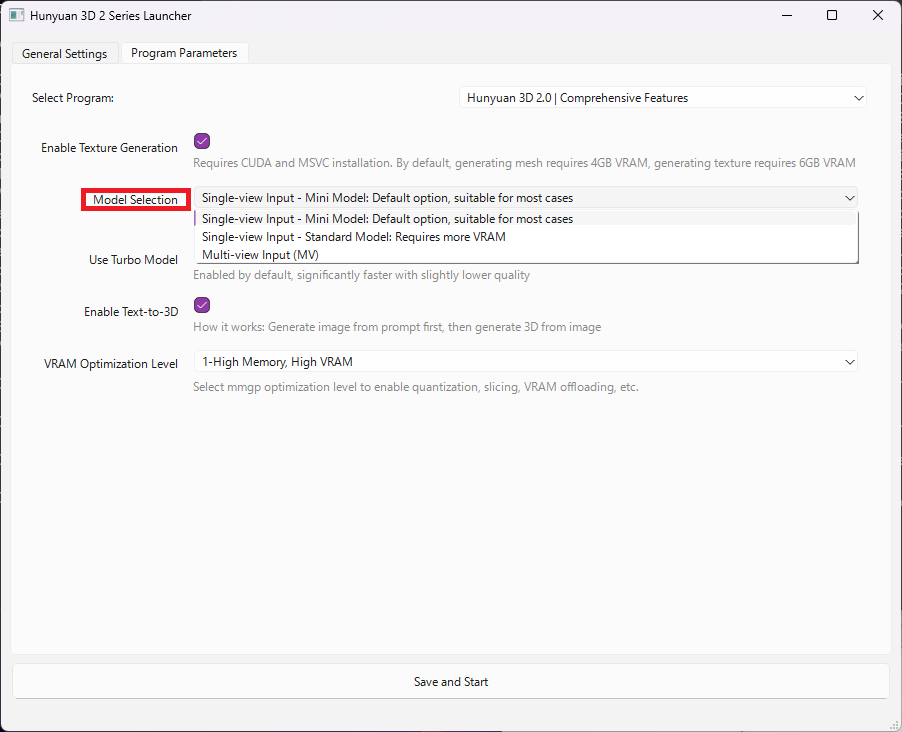
実行するプログラムとして「Hunyuan3D 2.0 |Comprehensive Features」を選択した場合、「Model Selection」の項目で使用するモデルを選択できます。
- Single-view Input – Mini Model : 単一画像から生成するミニモデル(デフォルト)。
- Single-view Input – Standard Model:単一画像から生成するスタンダードモデル。ミニモデルと比べて高解像度のテクスチャが生成されるが、より大きいVRAM容量を使用する。
- Multi-view Input(MV) : 1~4枚の三面図から3Dモデルを生成する。
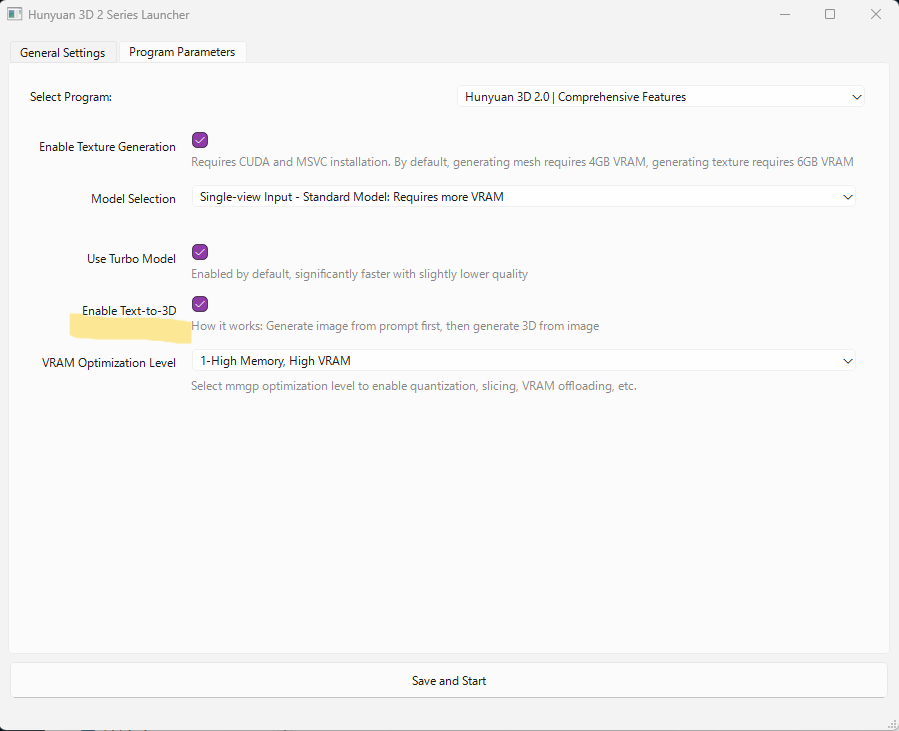
Launcherの「Program Parameters」には、他に3つの項目があります。
- Use Turbo Model: ONにすると、やや品質は下がるが生成時間が大幅に短くなる
- Enable Text-to-3D: ONにすると、テキストから3D生成を行う機能が有効になる
- VRAM Optimization Level
以下の例では、Use Turbo ModelをONにすると生成時間が3割程度短くなりました。(モデルの品質にはあまり差はありません)
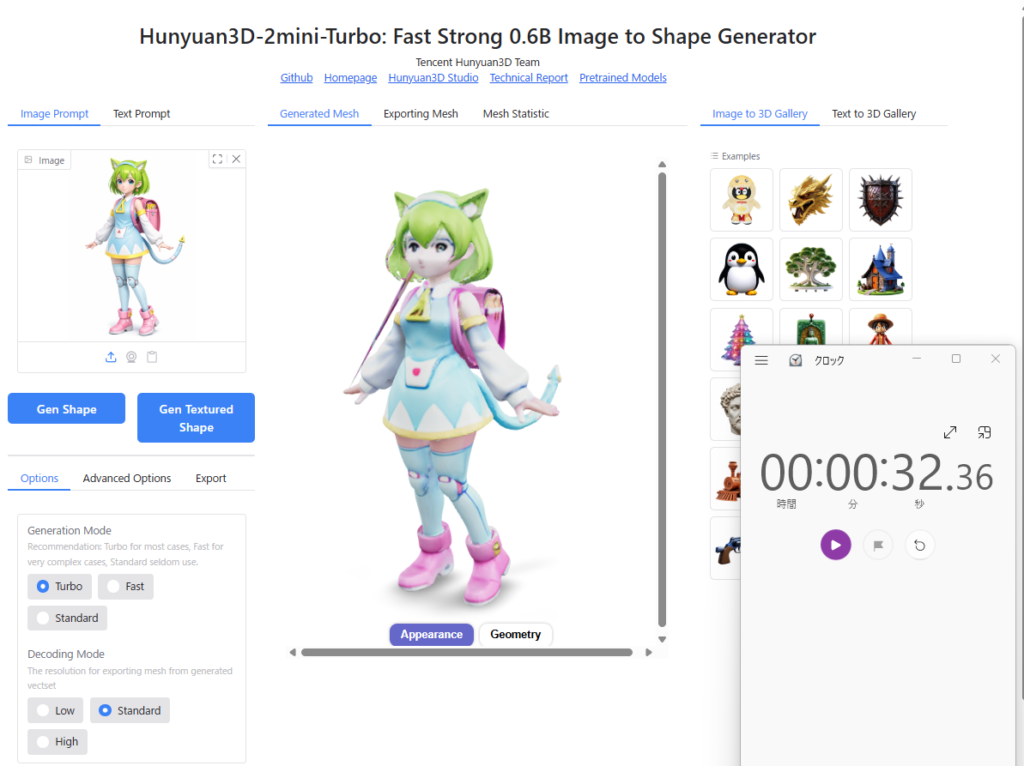
VRAM Optimization Levelについてですが、「mmgp」というメモリマネジメントプログラムが実装されており、mmgpのGithubの説明によれば1~5のハードウェア要件は以下とのこと。
- 1-High Memory, High VRAM: メモリ≧48 GB、VRAM≧24 GB
- 2- High Memory, Low VRAM: メモリ≧48 GB、VRAM≧12 GB
- 3- Low Memory, High VRAM: メモリ≧32 GB、VRAM≧24 GB
- 4- Low Memory, Low VRAM: メモリ≧32 GB、VRAM≧12 GB
- 5-Very low Memory, Low VRAM: メモリ≧24 GB、VRAM≧10 GB
ただし、Hunyuan3D 2.0ミニ版ではVRAM容量が抑制されているので、筆者の環境では1に設定しても問題なく動作しました。
単一画像から3Dモデルを生成・エクスポートするまでの流れ
ここからは、Hunyuan3D-2.0起動後に、単一画像から3Dモデルを生成・エクスポートするまでの流れを紹介します
モデルは「Single-view Input – Mini Model」を選択し、「Use Turbo Model」はオンにしています。
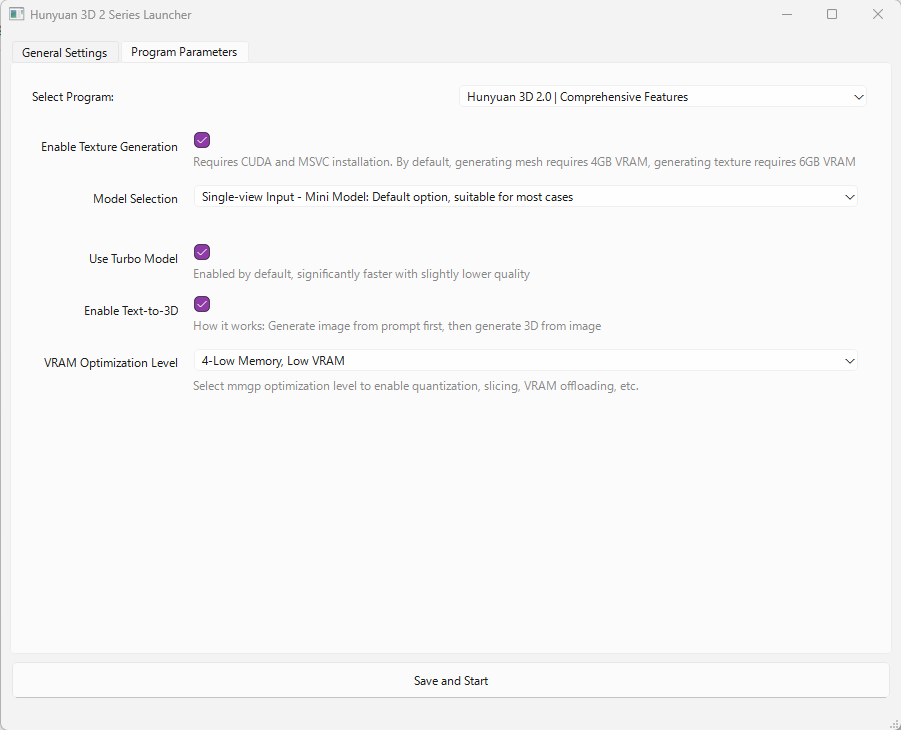
事前に、立ち絵のイラストを用意しておきます。
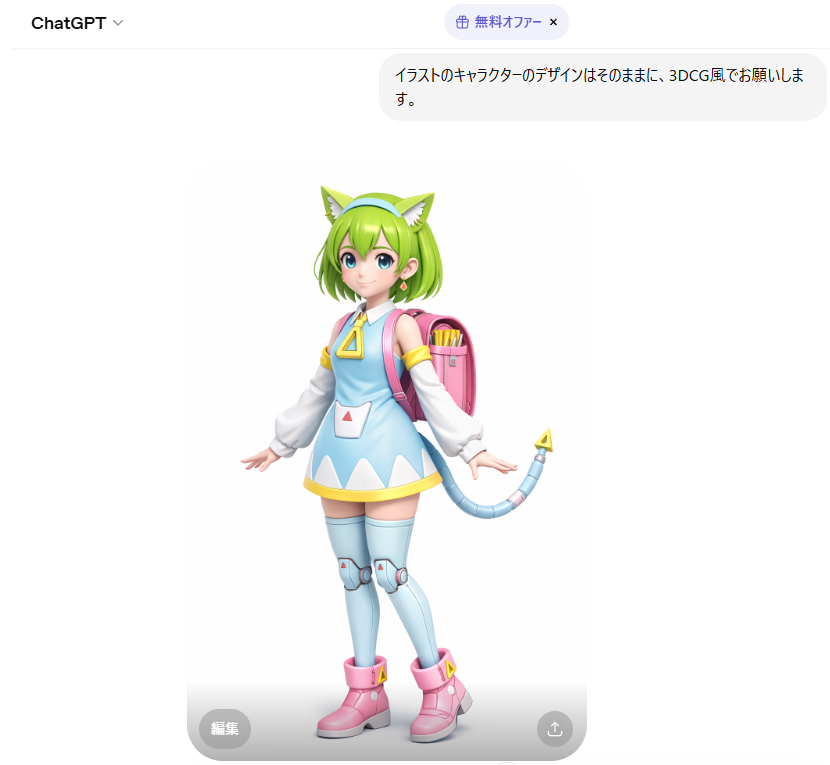
BlendAI株式会社のキャラクター「デルタもん」のイラストを、ChatGPTを使って3D風に変換したものをHunyuan3Dへのインプットとして使用します。
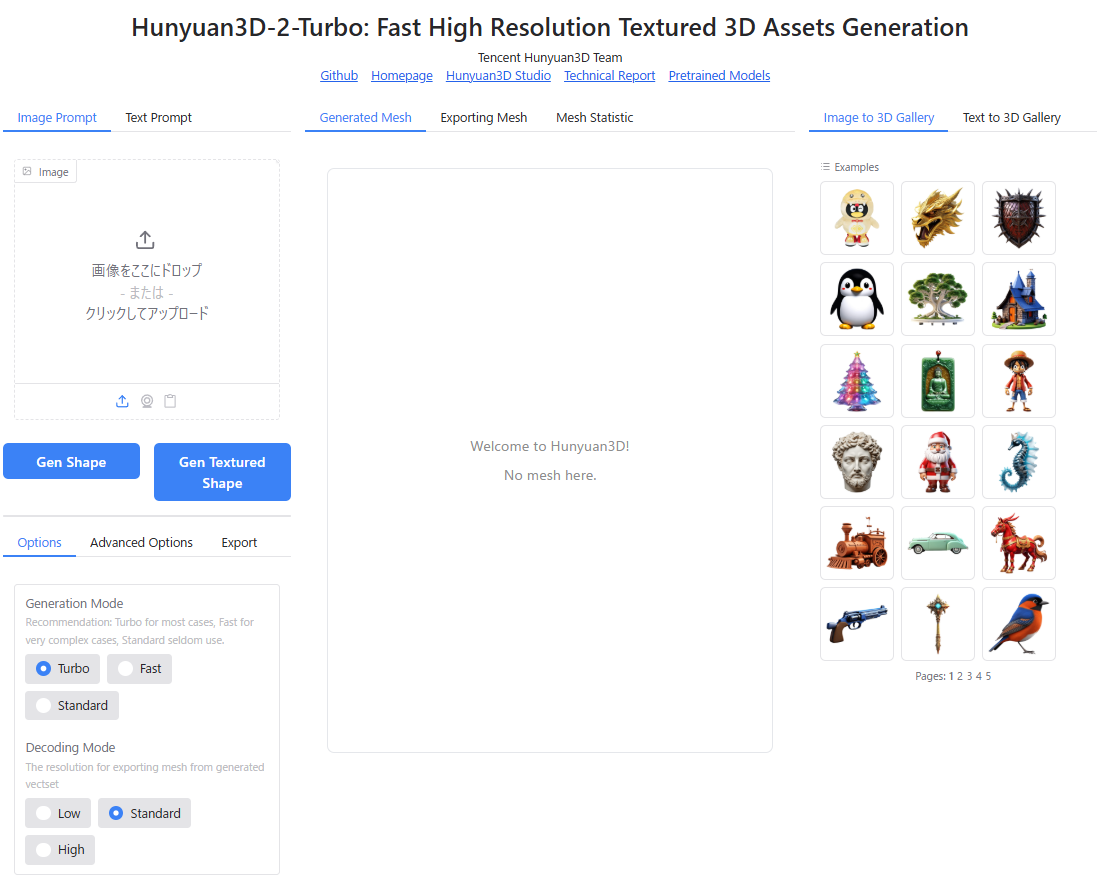
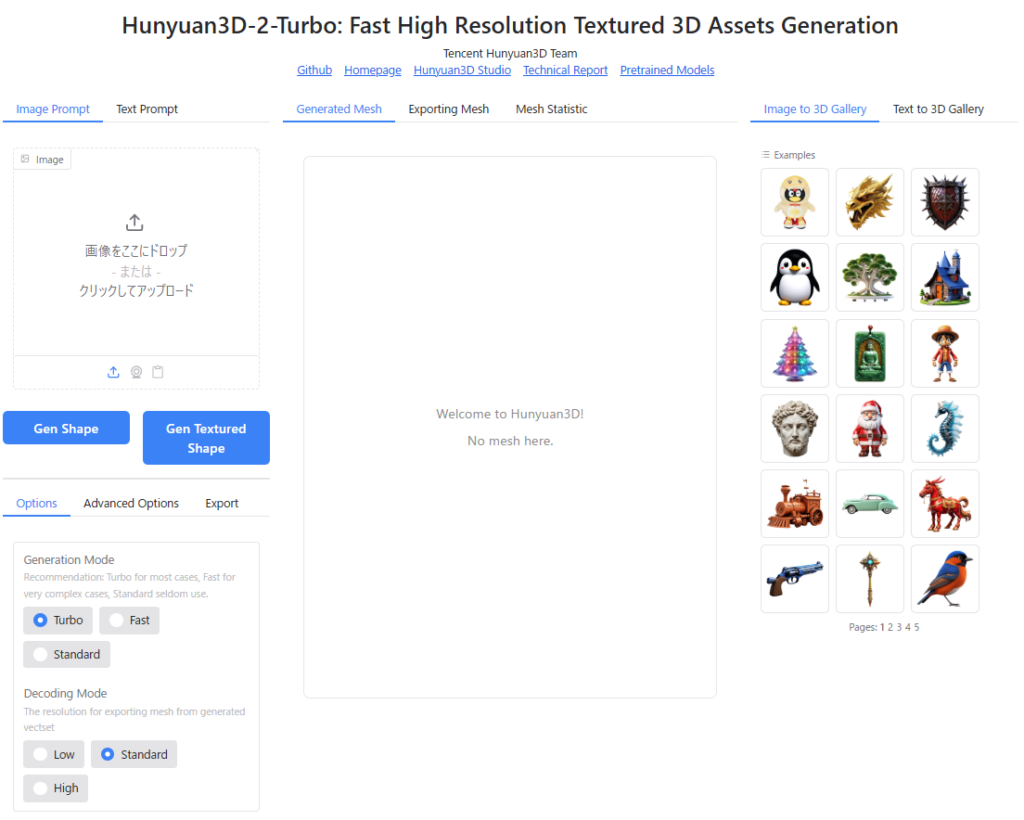
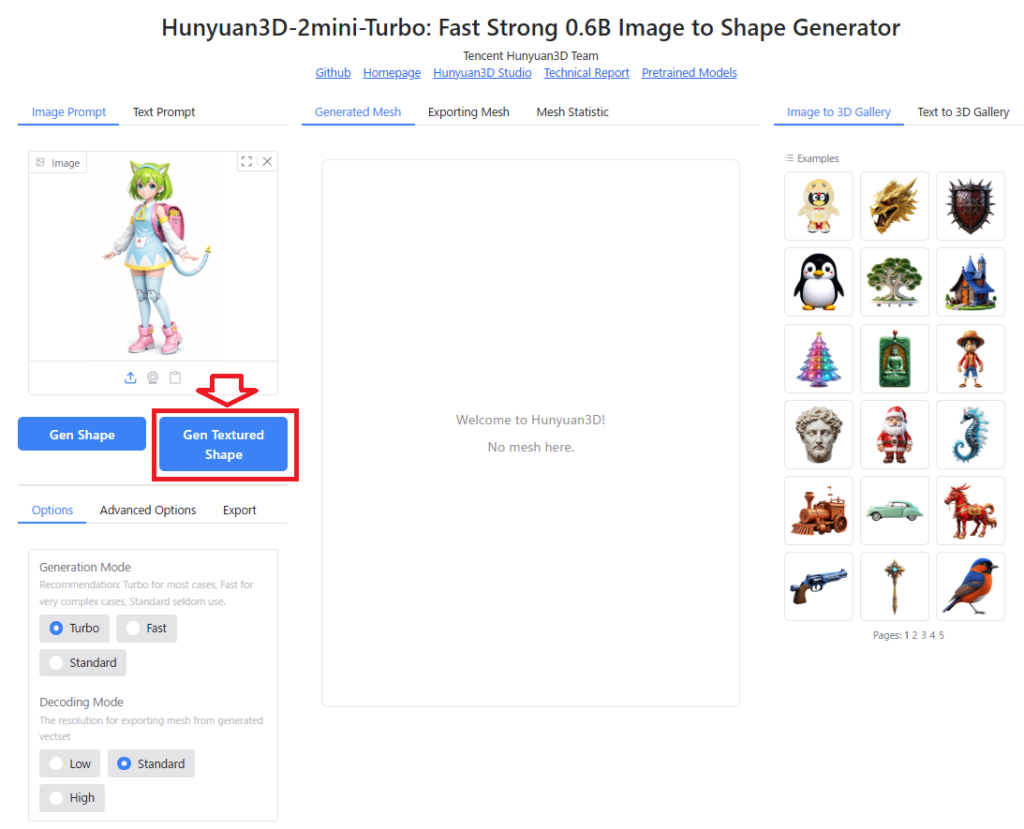
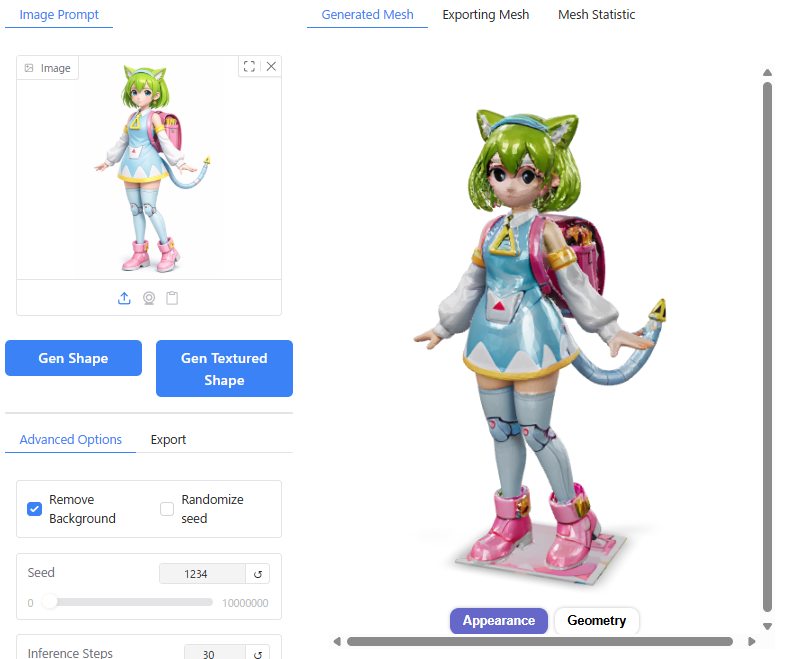
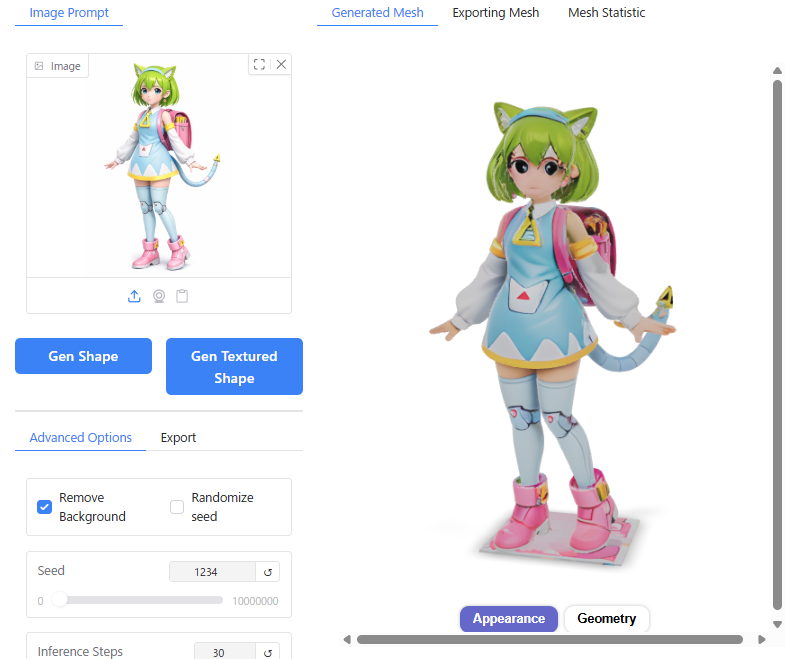
Hunyuan3Dの画面左上「Image Prompt」を選択し、「Image」のエリアに画像をドラッグアンドドロップすると、Hunyuan3Dに画像が読み込まれます。
「Gen Shape」のボタンをクリックすると、3Dモデル(テクスチャなし、形状のみ)が生成されます。
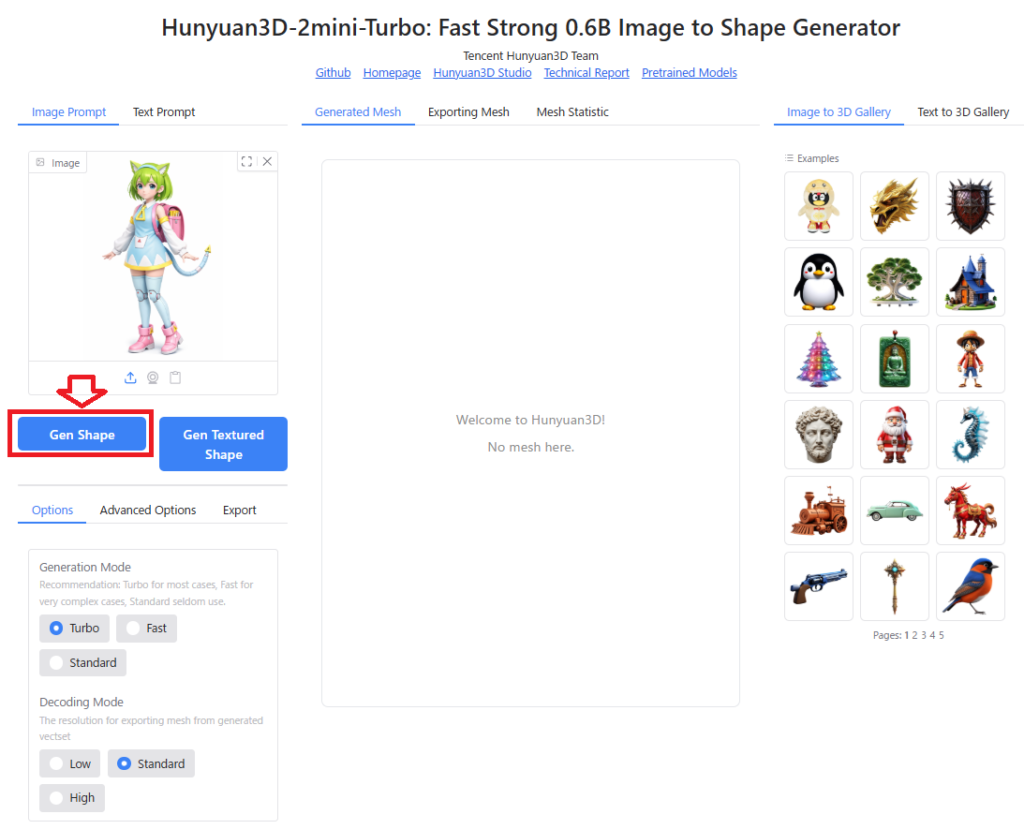
以下は実際に生成したときの動画ですが、筆者のRTX5060Tiの環境でたった7秒ほどで画像を元に3D形状を作ってくれました。
「Gen Textured Shape」をボタンをクリックすると、テクスチャ付きの3Dモデルが生成されます。
以下は実際に生成したときの動画ですが、メッシュ生成のみと比べて4倍ほど時間がかかりました(筆者のRTX5060Tiの環境で28秒ほど)。
メッシュが部分的な破綻があったり、テクスチャのディテールの解像度は低いですが、一応人物の顔・体として表現できています。

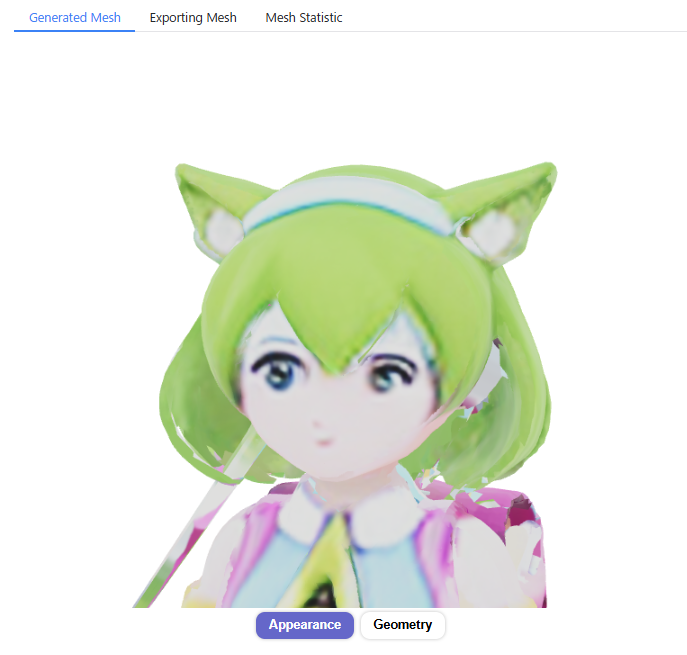
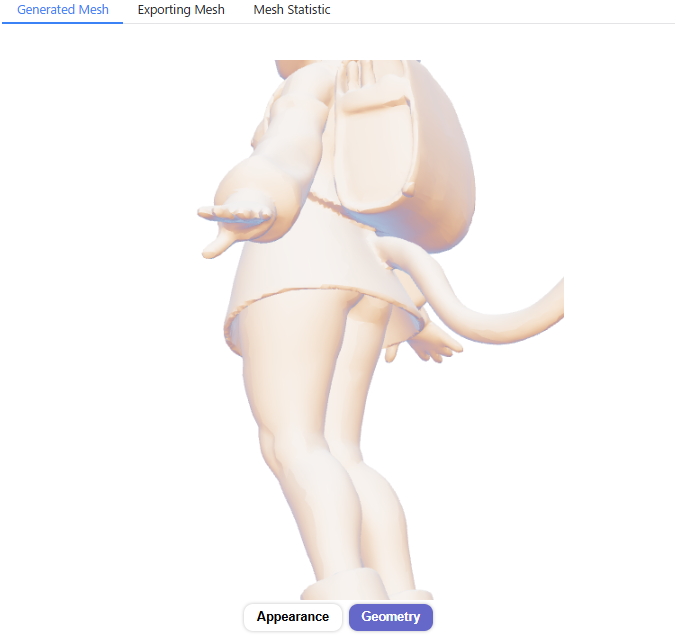
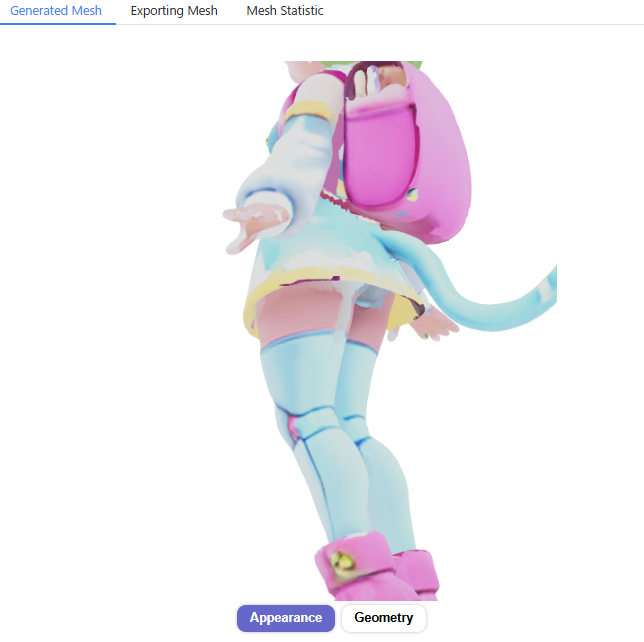
生成した3DモデルをBlenderなどの3DCGソフトにエクスポートするためには、画面左下の「Export」のタブを選択し、エクスポート用のポリゴンモデルに変換(Transform)する必要があります。
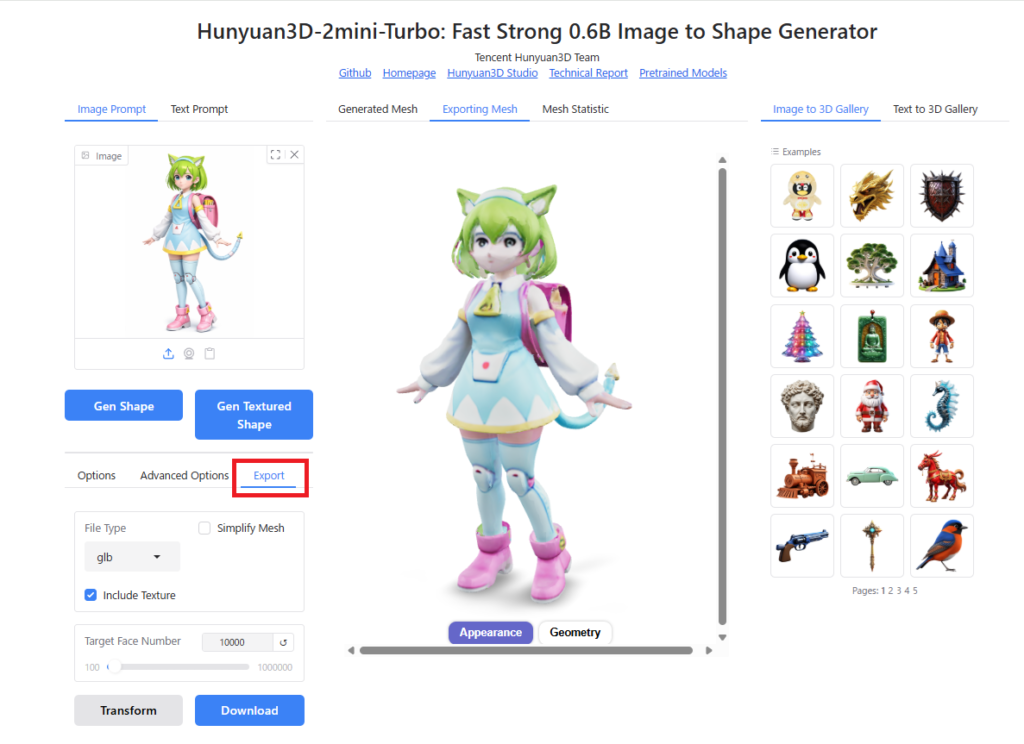
「File Type」では、glb, obj, ply, stlから3Dモデルの出力形式を選択できます。
「Include Texture」をオンにしておくことで、テクスチャ付のポリゴンモデルが生成されます(ただし、実際に試したところテクスチャ付モデルをBlenderにエクスポートできるのはglb形式だけでした)。
「Simplify Mesh」を選択するとモデルの形状を保ったままポリゴンを削減することができますが、テクスチャ付のモデルを生成した場合は有効化できませんでした。
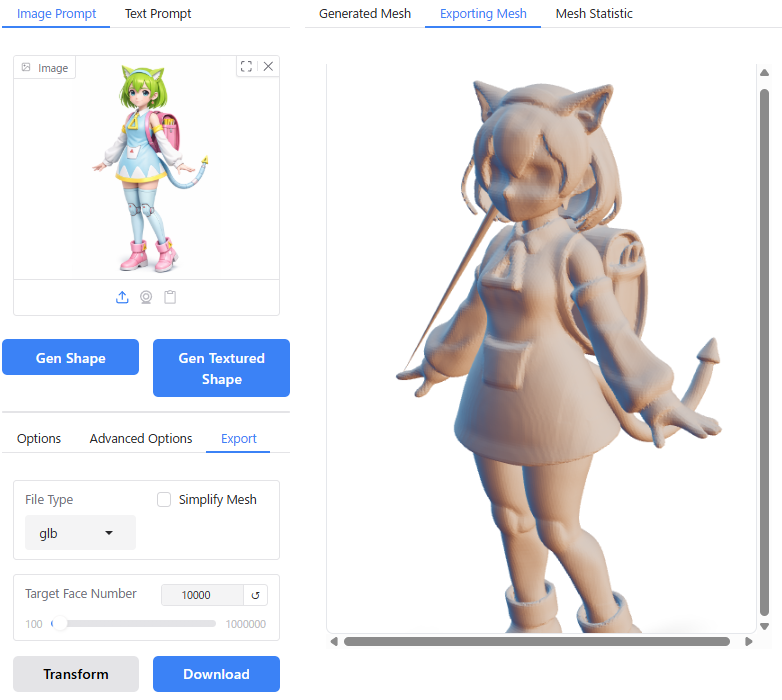
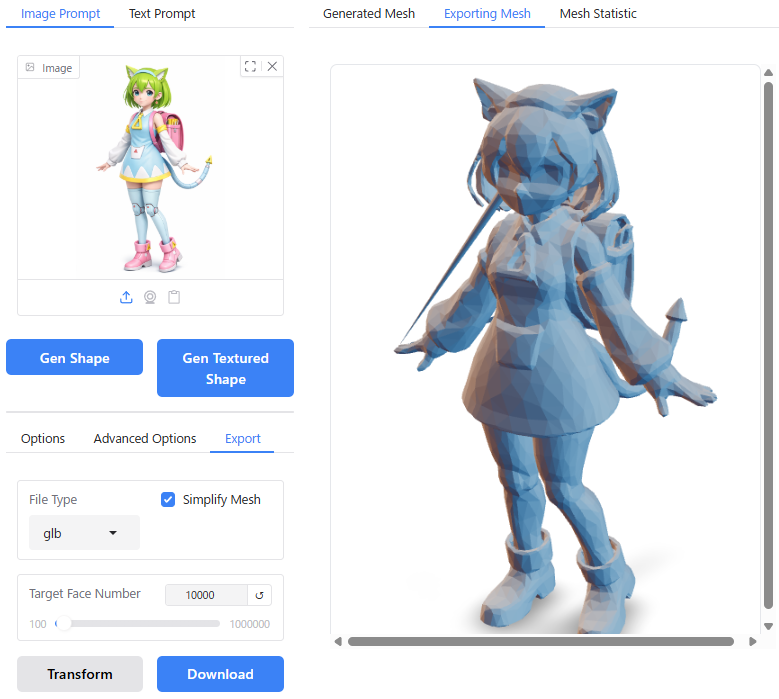
「Target Face Number」で、変換後のポリゴン数を設定します。
以上の項目を設定し、「Transform」をクリックするとポリゴンモデルが生成され、「Download」をクリックするとブラウザ経由でモデルがダウンロードされます。
ダウンロードしたglbファイルをBlenderの画面上にドラッグアンドドロップし、以下のようにテクスチャ付のモデルをBlender上で表示できました。
編集モードでポリゴン形状を確認すると、以下のように3角形で構成されているのがわかります。
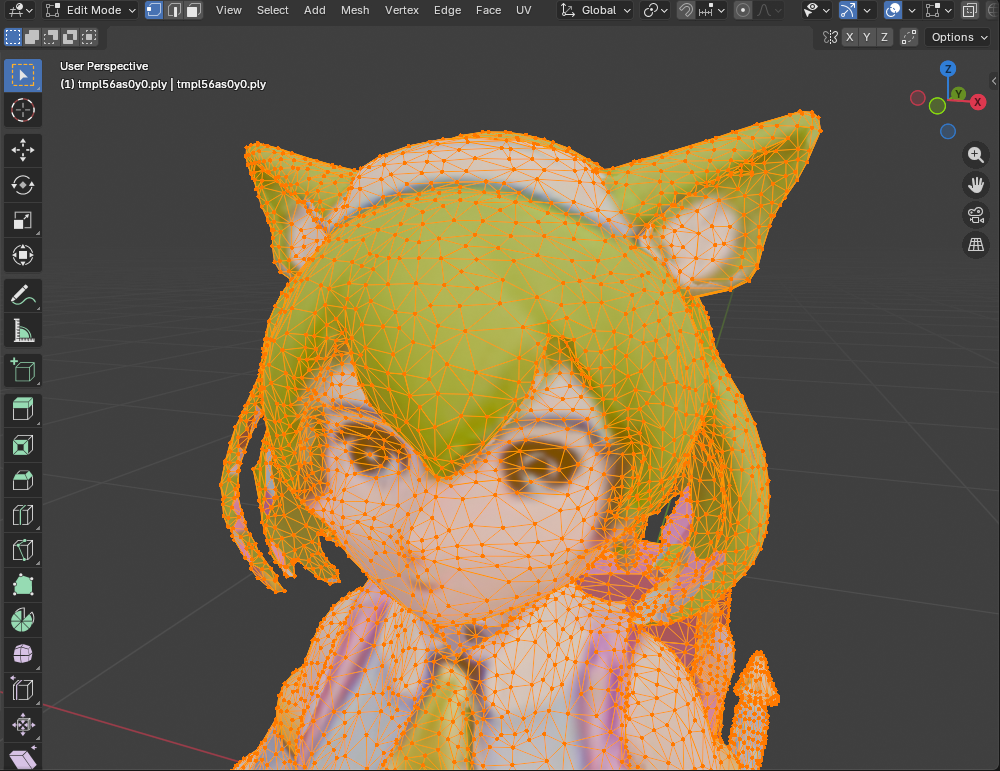
以上が、Hunyuan3D-2.0を使って、単一画像から3Dモデルを生成・エクスポートするまでの流れです。
設定による出力結果の違い
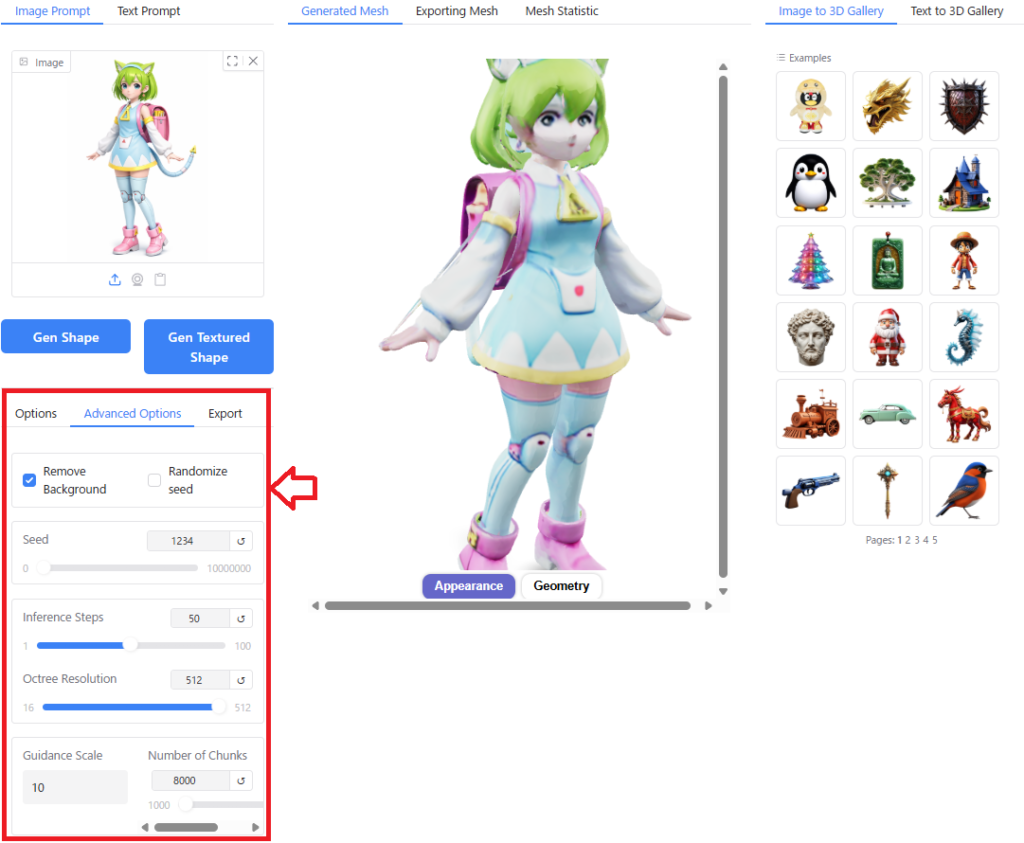
画面左下の「Options」「Advanced Options」の項目で、AI演算に使用するパラメータをチューニングすることができます。
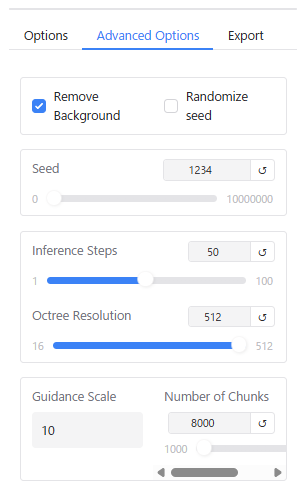
「Advanced Options」は詳細な設定メニューで、各項目の内容は以下のようになっています(説明はGoogle Geminiを参考にしました)。
- Seed: 生成プロセスのランダム性を制御。0以上の整数値で設定可能。同じ数値を設定するとほぼ同じアウトプットが生成される。
- Inference Steps: 推論ステップ数。数値が少ないほど計算時間は早くなるがメッシュの品質は粗くなる。
- Octree Resolution: 3Dグリッドの分解能。16~512で設定でき、数値を大きくするほど細部を表現できるが計算時間が長くなる
- Guidance Scale: 入力画像(またはテキスト)にどれだけ忠実に従うかを制御する。デフォルト値は5。数値を大きくするほど画像に忠実に従おうとするが、形状が不自然になったり、生成時間が長くなったりする場合がある。
- Number of Chunks: 演算する際のチャンク数(計算する際の分割数)。デフォルト値は8000で1000以上で設定可能。数値を大きくするとメモリ消費量は少なくなるが計算時間が長くなる。
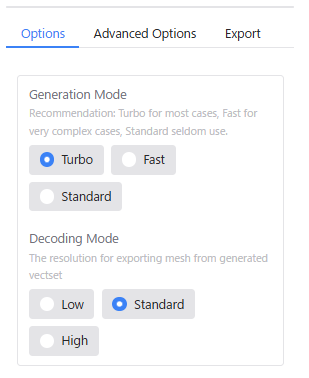
「Options」は、簡易的な設定メニューです。
「Options」の「Generation Mode」と「Decoding Mode」の項目は、「Advanced Options」の「Inference Step」と「Octree Resolution」に対応します。
| Optionsの項目 | Advanced Optionsの項目 |
|---|---|
| Generation Mode : Turbo | Inference Steps : 5 |
| Generation Mode : Fast | Inference Step : 10 |
| Generation Mode : Standard | Inference Step : 30 |
| Decoding Mode : Low | Octree Resolution : 196 |
| Decoding Mode : Standard | Octree Resolution : 256 |
| Decoding Mode : High | Octree Resolution : 384 |
各パラメータの数値を変えたときに、生成結果がどうなるか比較検証してみましたので、結果をざっとお見せします。
結論としては、基本的にデフォルト設定のままでよくて、ディテールの品質を上げたい場合にOctree Resolutionの値を大きくする(場合によってはSeed, Inference Steps, Guidance Scaleも調整)のがおすすめです。
Seed
Seedの数値を変えると、生成結果のバリエーションに影響して顔つきが微妙に変わってきます。
メッシュの破綻が生じる場合も、Seedの値を変えると発生しなくなったりしています。
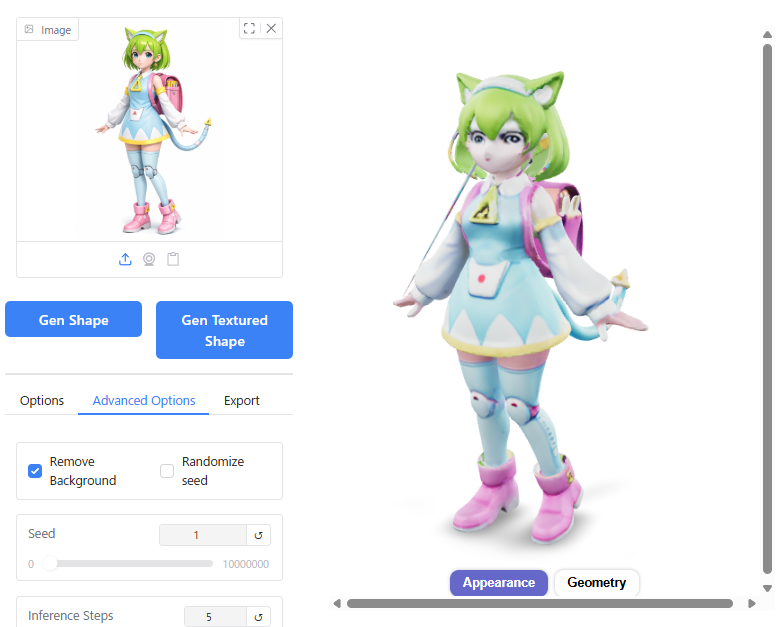
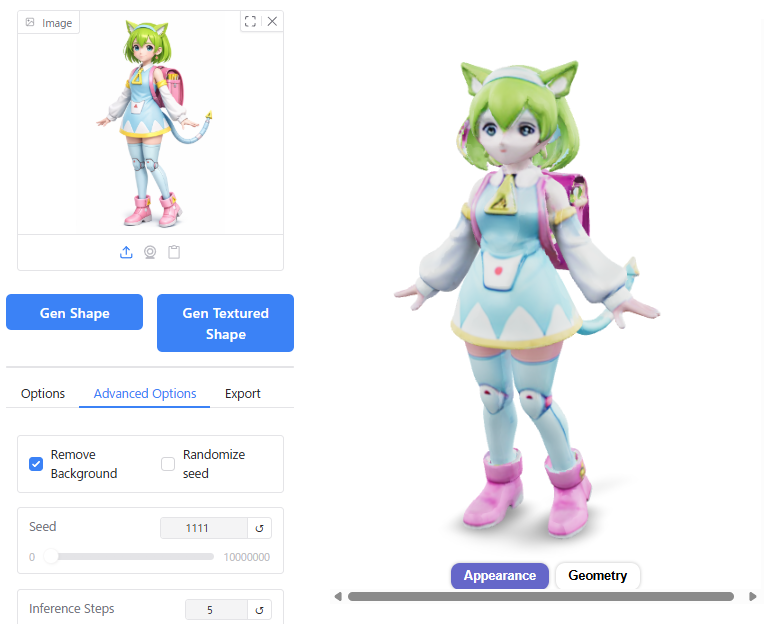
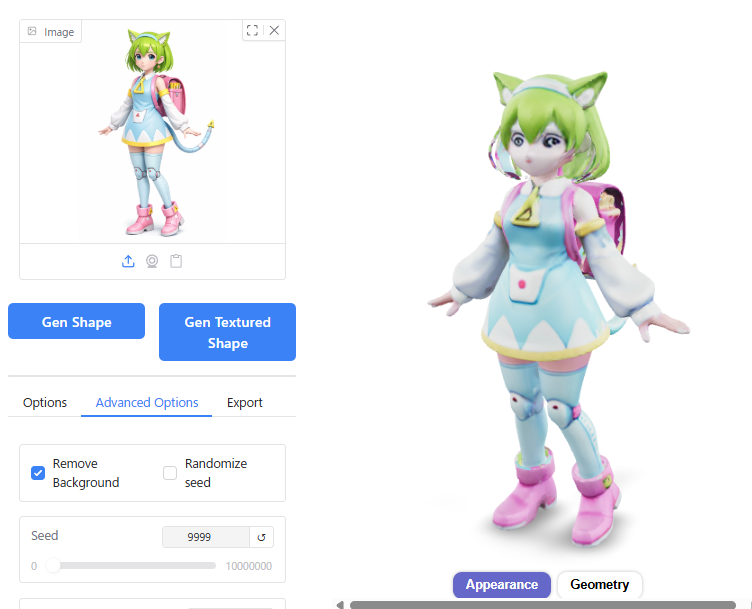
Inference Steps
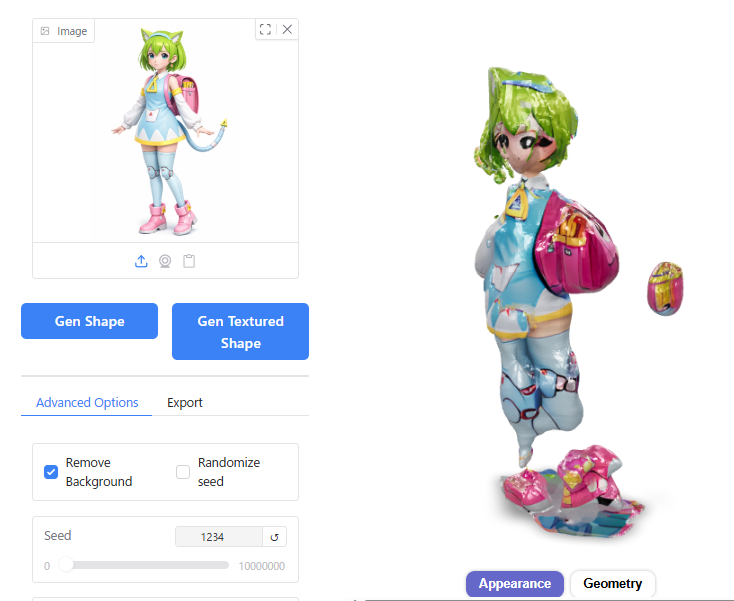
Seedの数値を1234にしてInference stepをデフォルトの5から大きくしたところ、3D形状が破綻してしまいました。
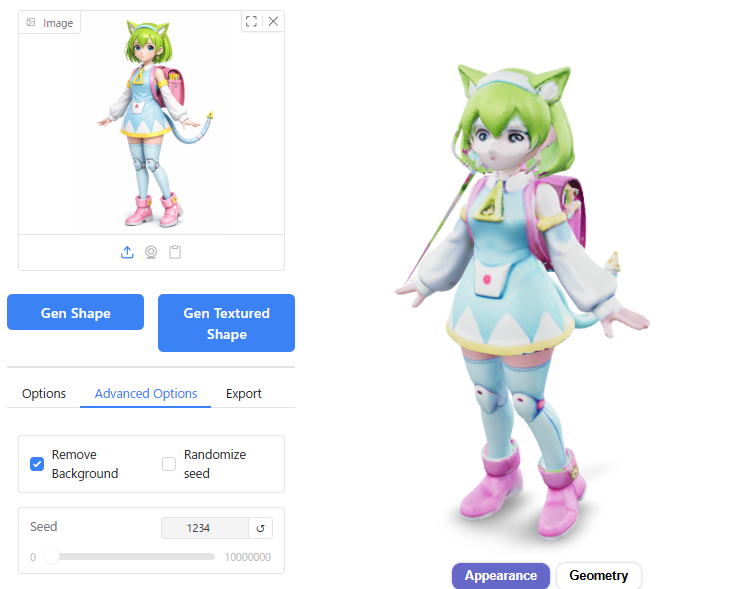
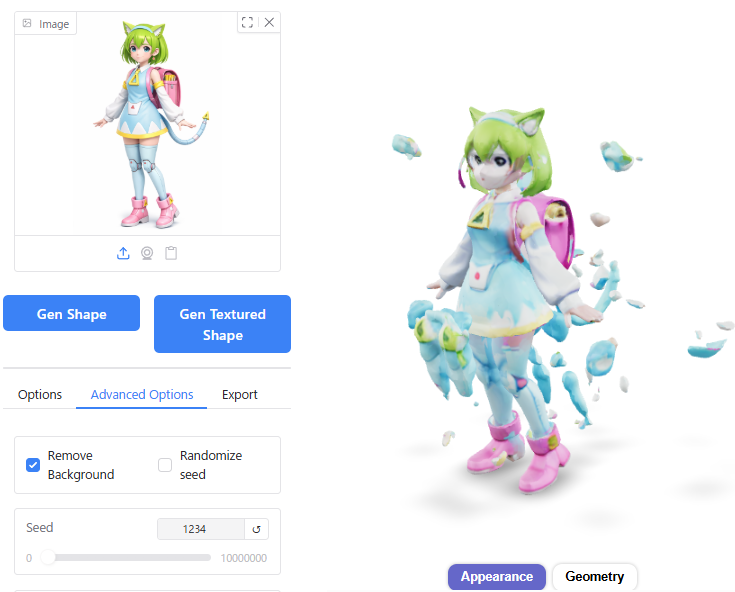
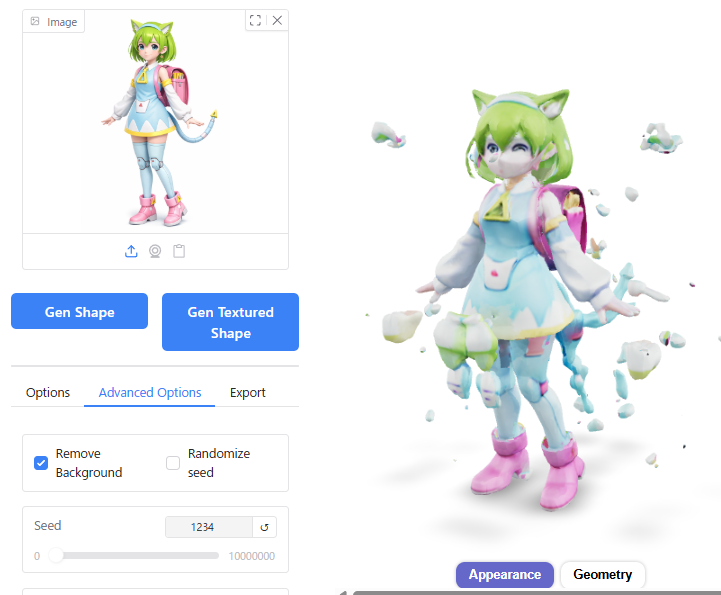
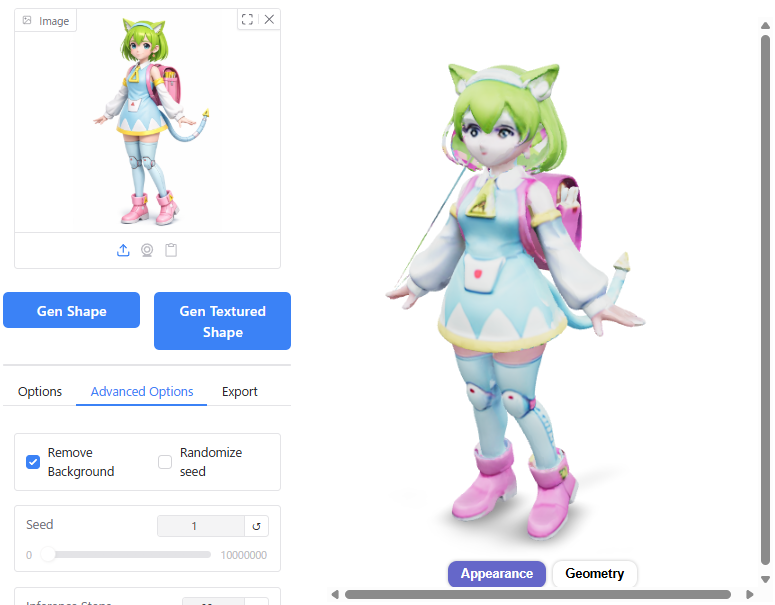
Seedの値を変えて試してみたところ、Seed 1ではうまくいきました。若干、顔つきが元画像に近くなっているように見えます。
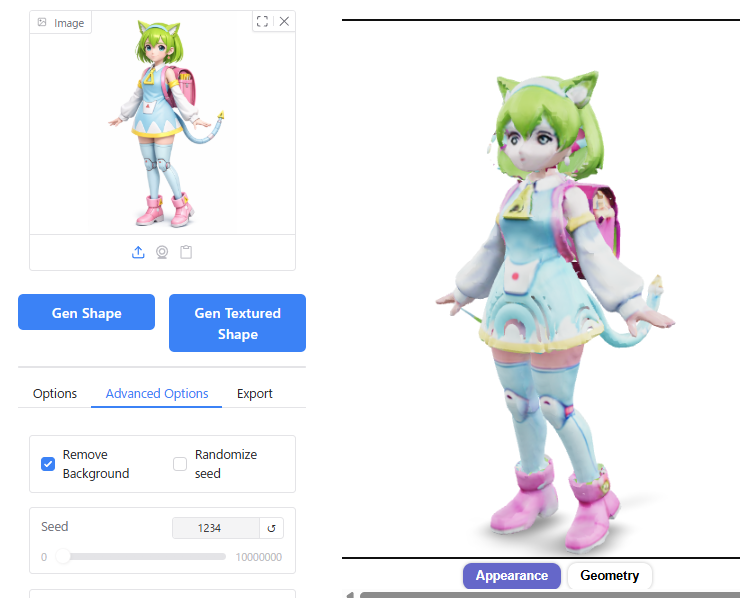
Octree Resolution
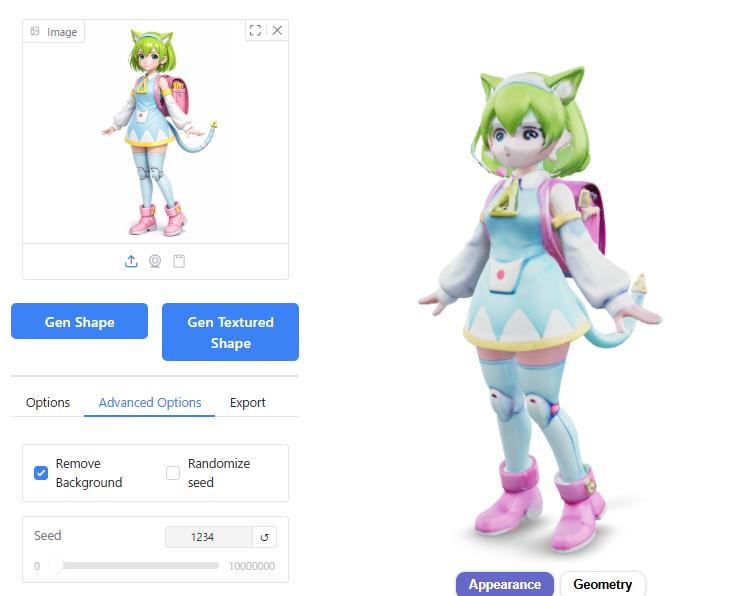
Octree Resolutionの数値をデフォルトの256から変えてみたところ、128ではスカートや髪の毛に不自然な凹凸が出てしまいました。
Octree Resolution =512ではメッシュの破綻がなくなりモデルの品質が向上しましたが、生成にかかる時間が23秒→32秒と10秒近く長くなりました。

Guidance Scale
Guidance Scaleの値を大きくしたところ、メッシュの破綻は改善されました。
ただし、それ以外のモデルの品質はそこまで大きく変わらないように見えます。
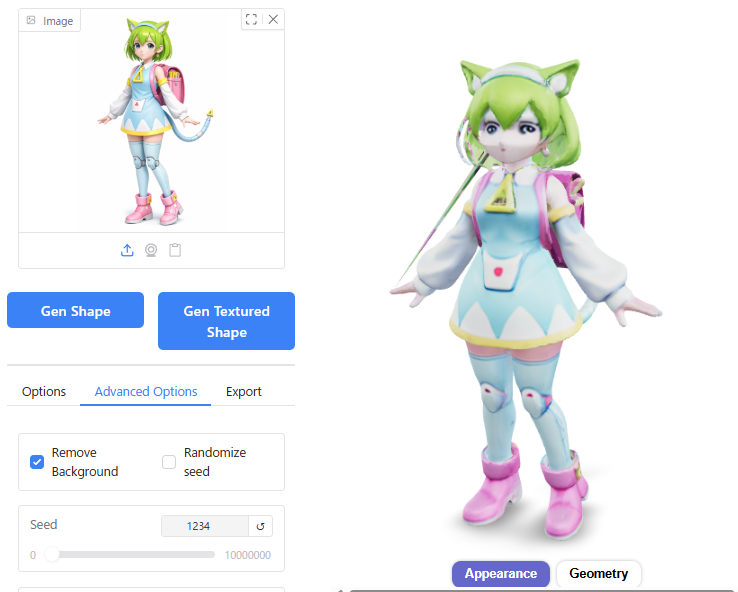
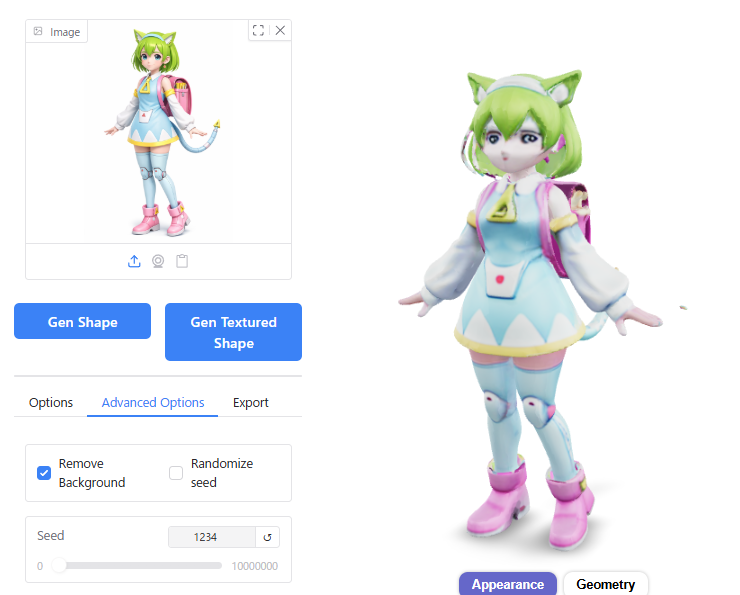
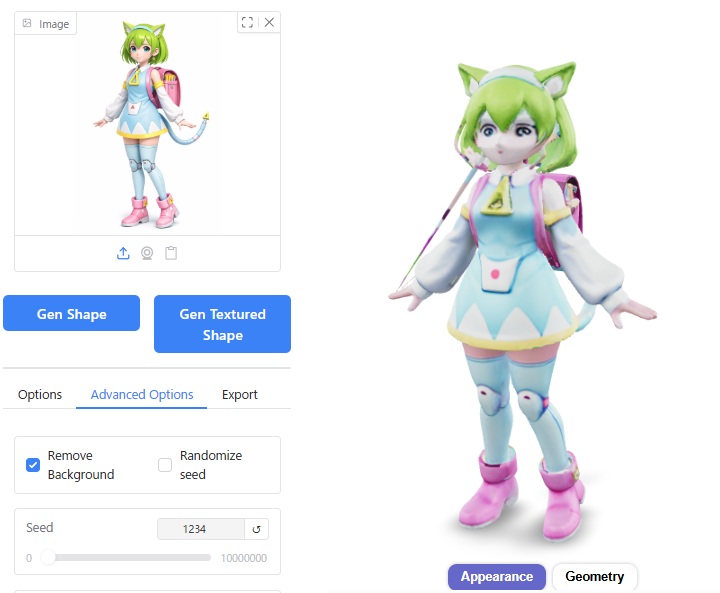
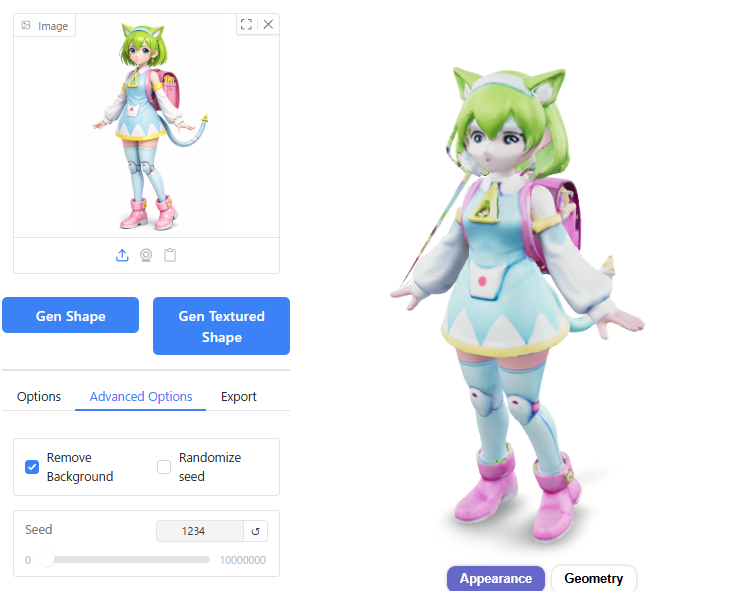
Number of Chunks
Number of Chunksをデフォルトの8000から1000、80000に変えてみましたが、生成結果にほとんど影響はありませんでした。
数値を大きくすると、生成にかかる時間が23秒→25秒と2秒程度長くなりました。
いろんな画像の出力結果
デルタもん以外にも、さまざまな画像の出力を試してみました。
キャプチャ画像を載せておきます。
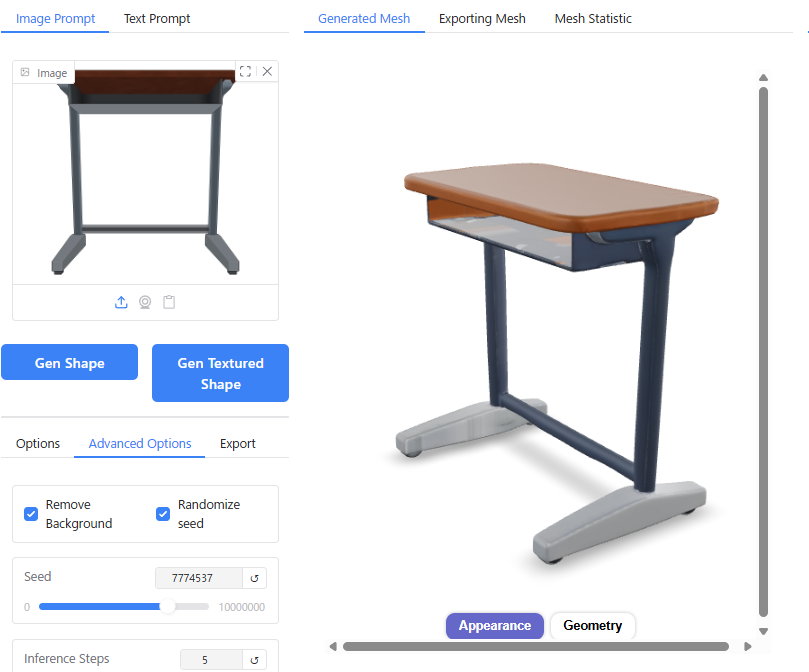
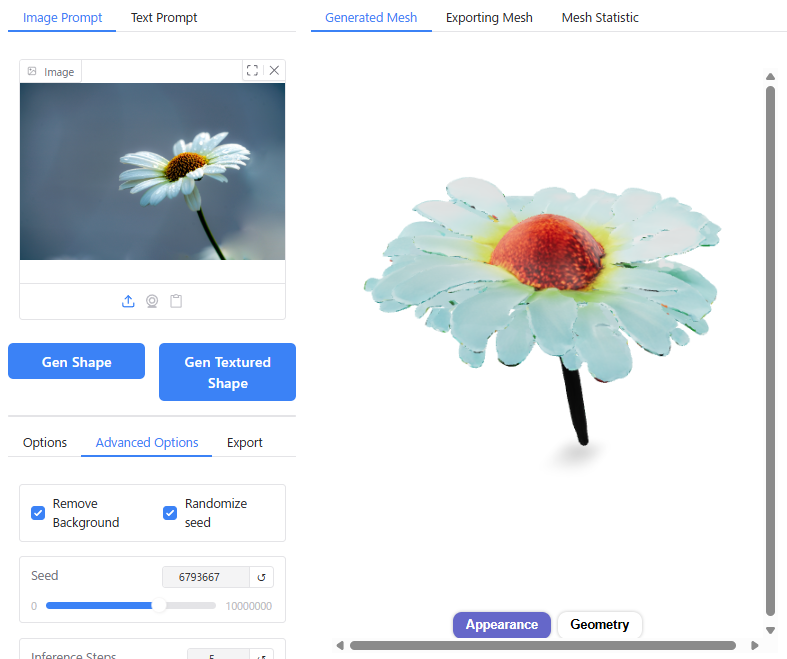
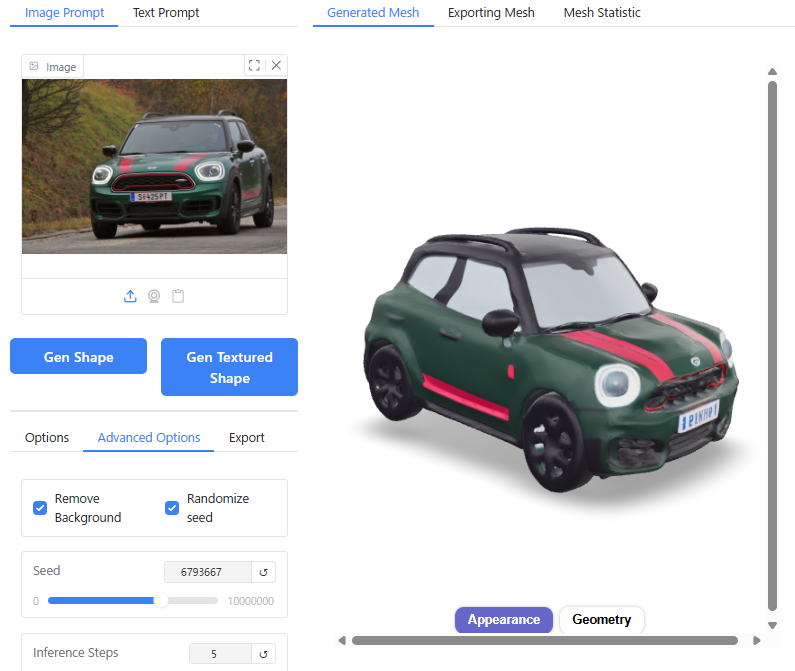
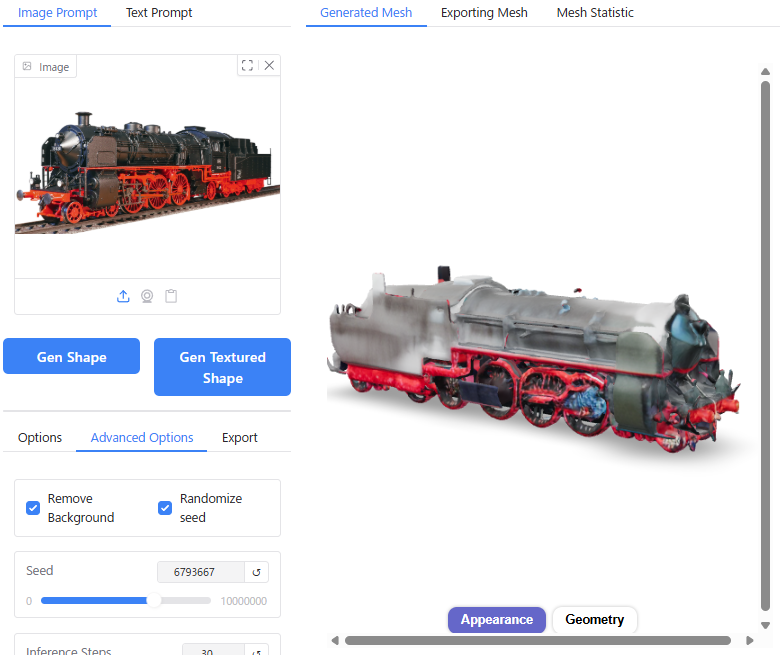
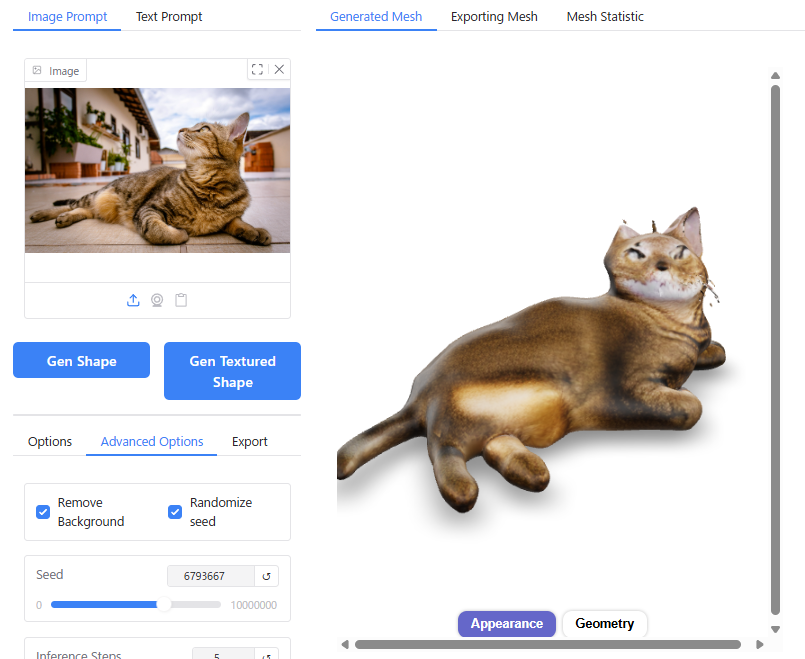
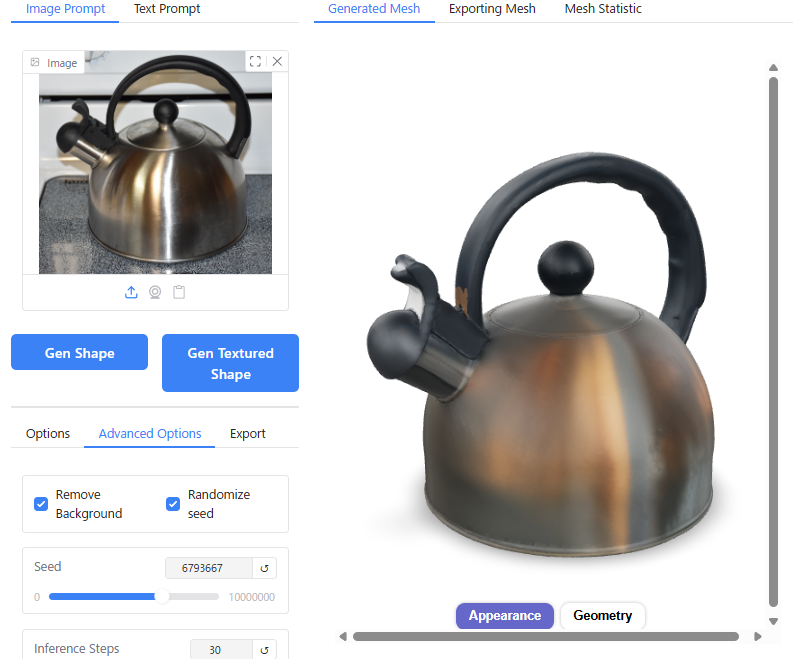
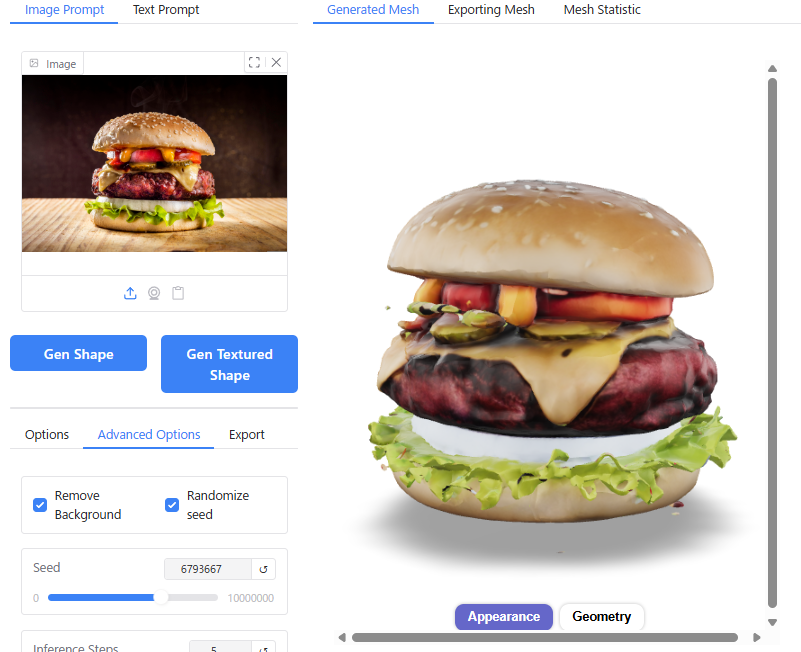
単純な形状のものについては実際の3D形状をよく再現できていますが、複雑な形状のものについてはディテールが省略されてしまう傾向があります。
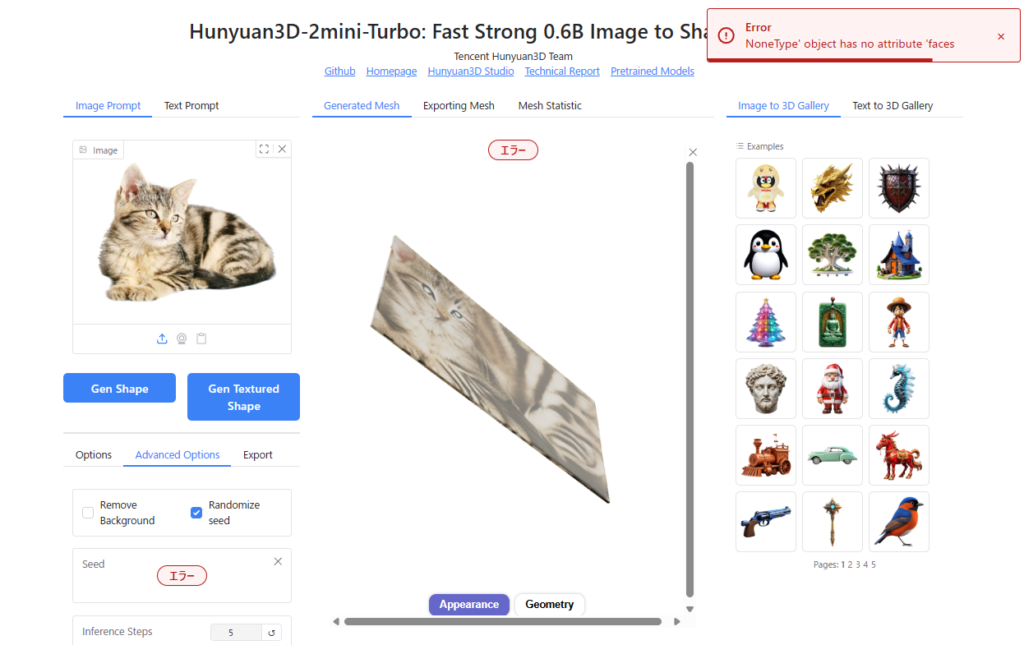
特に、人間以外の生き物については、学習データが足りないからか苦手なようです。
猫の画像によっては、Hunyuan3Dが立体形状を正しく認識できないためかエラーがでてしまったり、3D形状ができず「猫の模様をした平面状の何か」ができてしまいました。
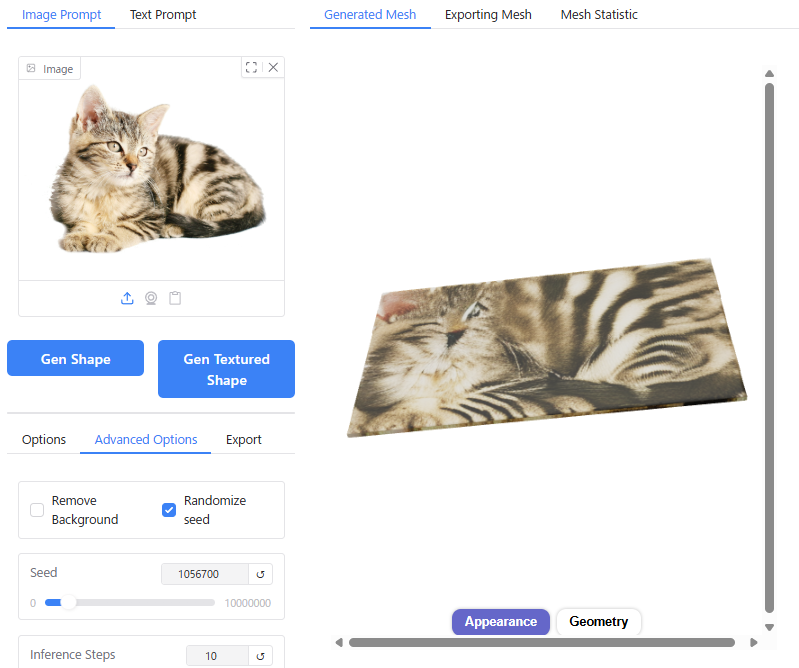
画面右の、プリセットの画像から作成することもできます。
プリセット画像をクリックまたはドラッグアンドドロップで設定できます。
テキストプロンプトから生成する方法
Hunyuan3D-2.0には、テキストプロンプトから3Dモデルを生成する機能があります。
この機能を使用するには、Launcherの設定で「Enable Text-to-3D」をONにしておく必要があります
「Image Prompt」に何も画像を貼らない状態で、画面左上の”Text Prompt”に作成したい3Dモデルを表現するプロンプト(命令文)を打ち込み、「Gen Shape」または「Gen Textured Shape」をクリックします。
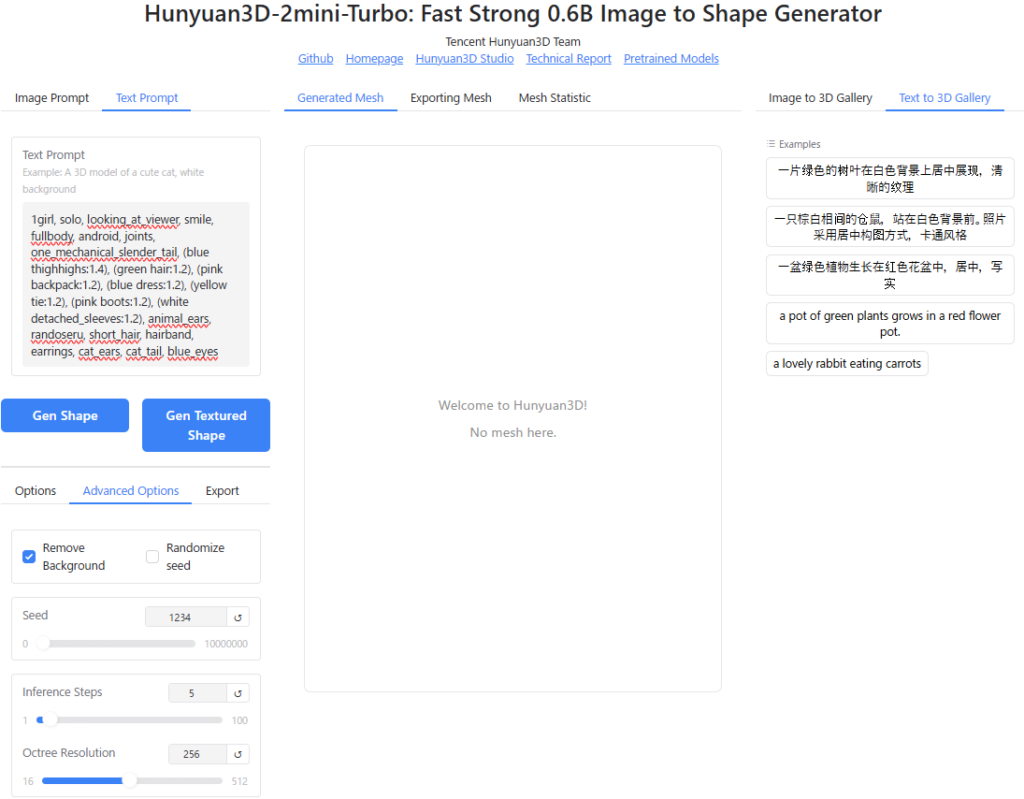
試しに、BlendAI株式会社のホームページに記載の、デルタもんを生成するためのプロンプト(英語)を入力してみます。
1girl, solo, looking_at_viewer, smile, fullbody, android, joints, one_mechanical_slender_tail, (blue thighhighs:1.4), (green hair:1.2), (pink backpack:1.2), (blue dress:1.2), (yellow tie:1.2), (pink boots:1.2), (white detached_sleeves:1.2), animal_ears, randoseru, short_hair, hairband, earrings, cat_ears, cat_tail, blue_eyes以下のような出力結果になりました。
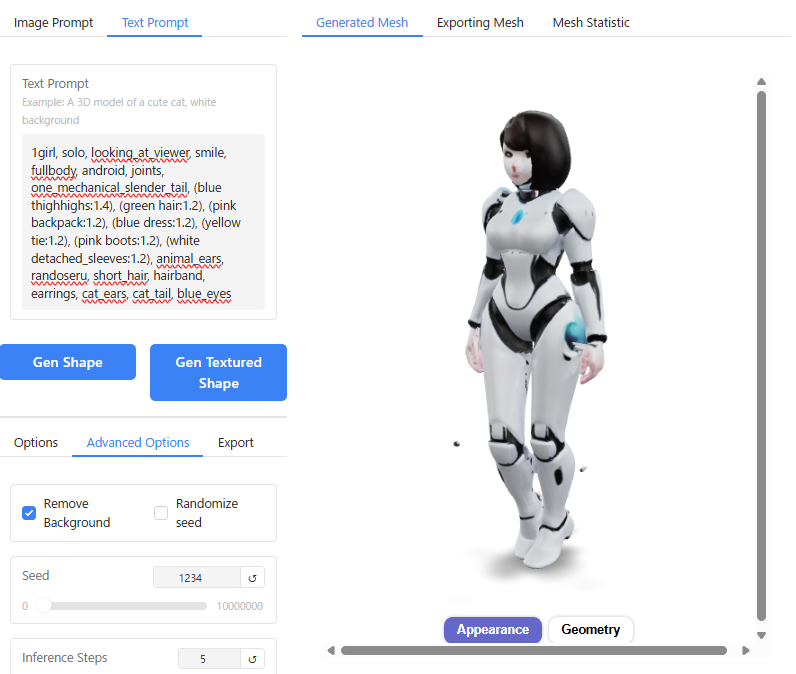
情報量が多すぎてAIが処理しきれないのか、"girl","android","joints"の部分は反映されていますが、猫耳やランドセル、機械の尻尾といったディテールが全く反映されていません。
ちなみに、Image Promptから生成する方法と比べて3倍以上時間がかかりました。
生成AI ChatGPTの力を借りてHunyuan3D用にプロンプトを書き直してみましたが、結果はあまり変わりませんでした。
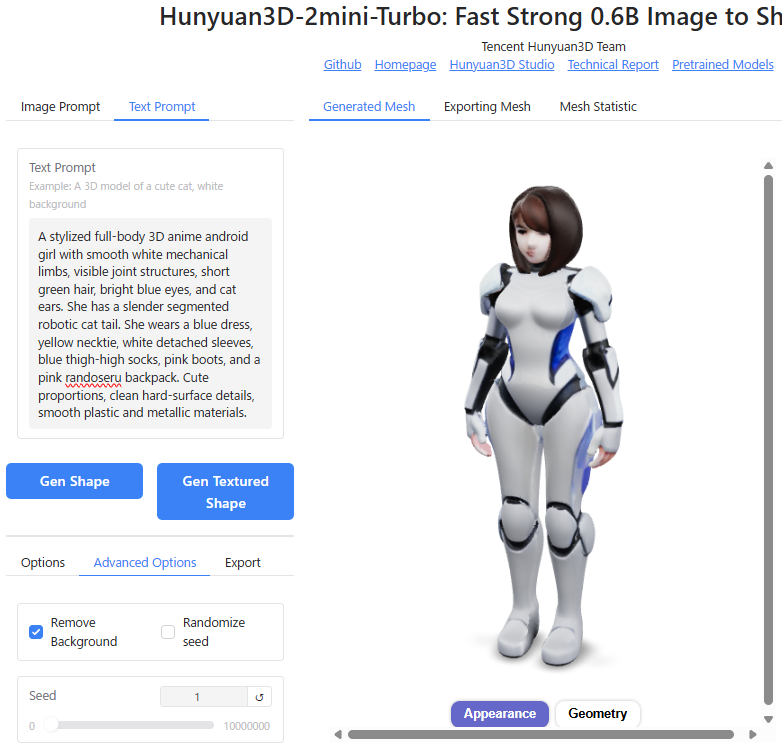
正直、Hunyuan3D-2のText promptは精度的にはあまり使い物にならないレベルなので、Stable DiffusionやChat GPTなどの他の画像生成AIでText promptから作成した画像をImage Promptとして使用する使い方をおすすめします。
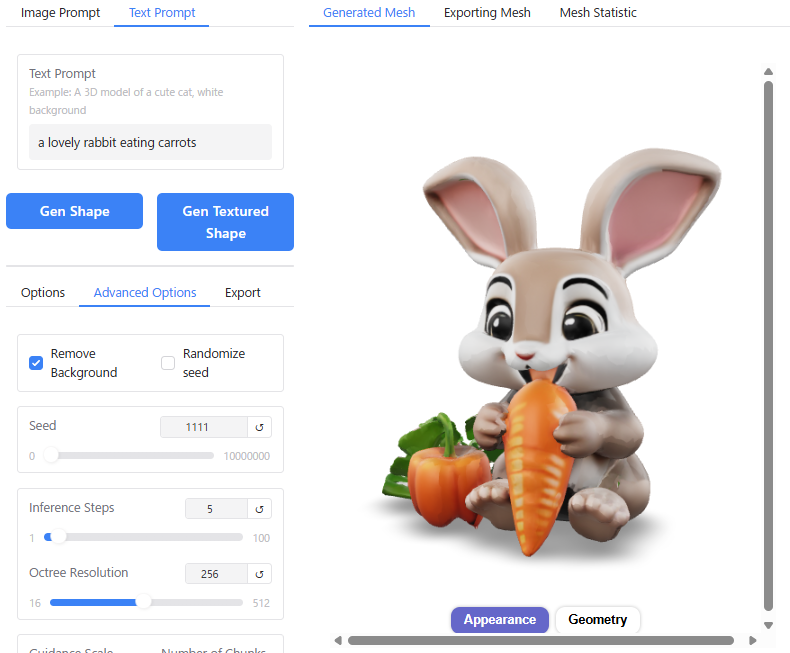
ちなみに、”a lovely rabbit eating carrots”など簡単なプロンプトであれば、以下のようにアニメキャラ風のモデルを生成してくれます(なんとなくDi〇neyのキャラクターっぽい感じですね)。
複数の画像から生成する方法
Hunyuan3D-2.0の”Model Selection”で”Multi-View Input(MV)”を選択した場合は、複数の画像から3Dモデルを生成することができます。
正面図1枚のImage Promptから見えない反対側の形状は不正確になりがちですが、MVを使うことで、360°正確に近い立体形状を作ることができます。
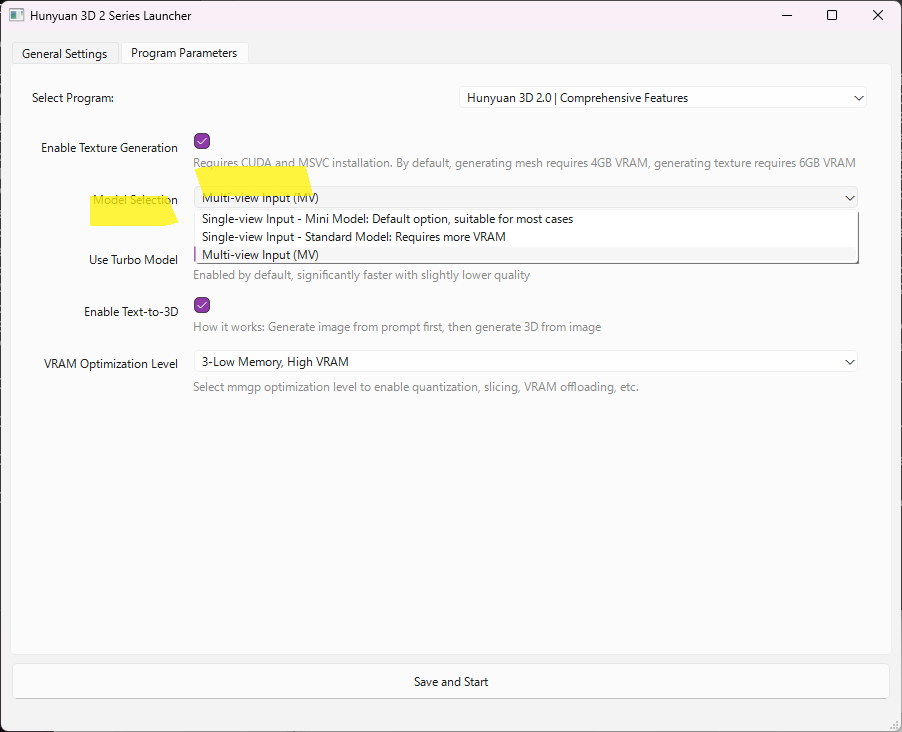
”Multi-View Input(MV)”を選択して起動すると、”Hunyuan3D-2mv-Turbo: Fast Image to 3D Generation with 1-4 Views”の画面が立ち上がります。
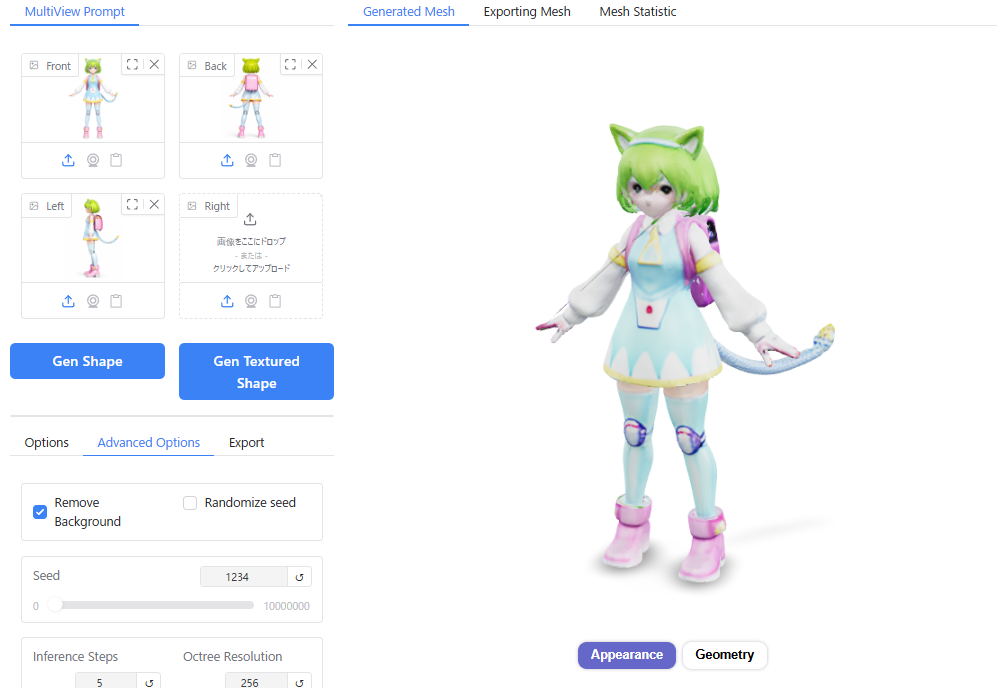
画面左上の”MultiView Prompt”のところに、前後左右の画像(1枚もしくは一部でもOK)をドラッグアンドドロップで画像を読み込ませます。
1枚絵の時と比べて生成するのに10秒ほど時間が長くかかりましたが、前後左右のインプット画像から、かなり正確な立体形状を作ってくれました。
1枚絵から作成した場合(左)と3面図から作成した場合(右)を比較すると、後ろ側のランドセルの形状などが正確に表現できています。
ただ、残念ながらテクスチャのクオリティは若干下がっているように見えます。

Hunyuan3D-2.1
Hunyuan3D-2.0のほかに、より新しいバージョンであるバージョン2.1を使うことができます。
テキストプロンプトとMulti-View Input(MV)は使うことができず、また生成時間もかなり長くなってしまいますが、その代わりバージョン2.0と比べて画像に忠実な形状・テクスチャが生成できるので、よりクオリティの高い3Dモデルを作ることができます。
使用方法はバージョン2.0と同じです。
ただし、バージョン2.0では20~30秒程度で生成できたのに対して、バージョン2.1では3分近くかかりました。
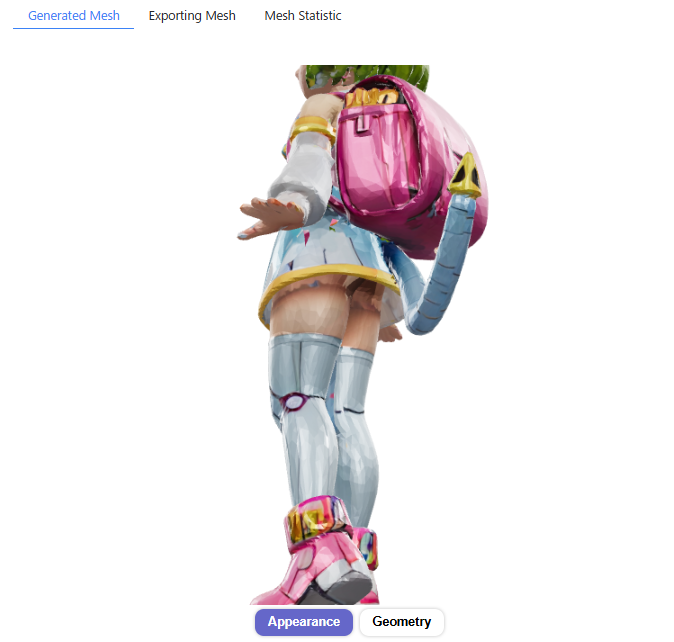
Hunyuan3D 2.0とバージョン2.1を比較すると、以下のようになります。
バージョン2.1の形状・テクスチャはバージョン2.0と比べて元画像を忠実に再現しており、またテクスチャに光沢が追加されているのがわかると思います。
ちなみに、私の環境だけかもしれませんが、バージョン2.1を使用している際に気になる点が2点ありました。
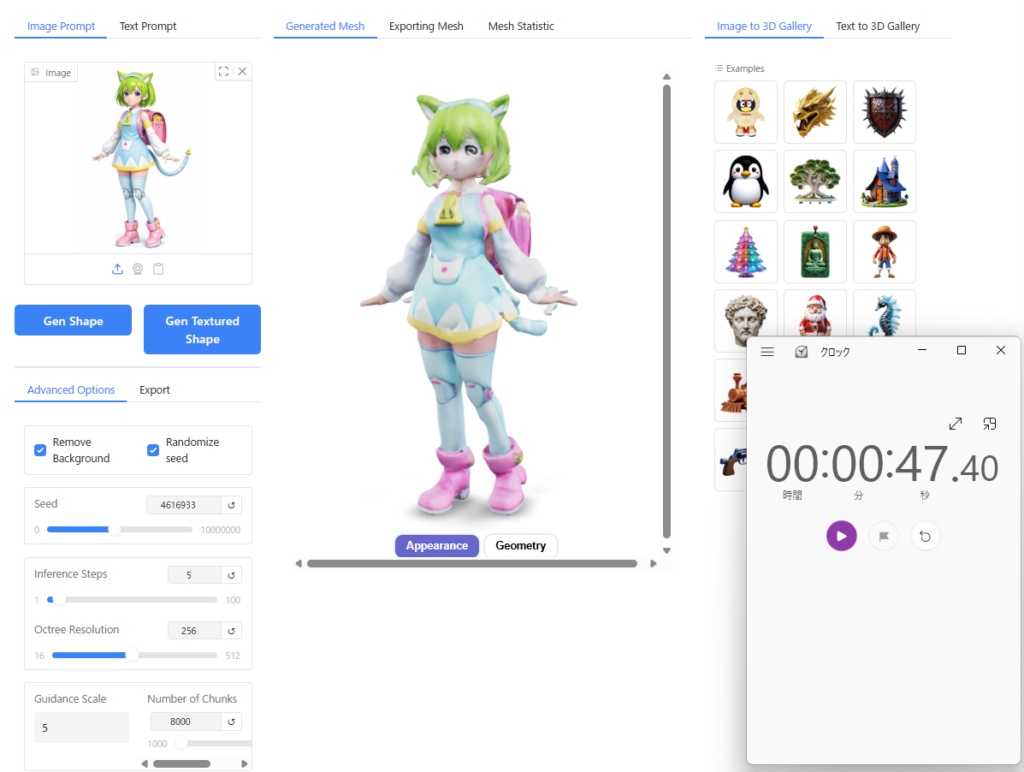
”Appearance”の見た目が変わる
”Geometry”をクリックしてから”Appearance”をクリックすると、なぜか光沢がなくなります。
光沢がないほうがセルルックっぽくなるので個人的には後者の見た目が好きですが、おそらくバグなのではないかと思います。
”Randomize seed”を有効にするとエラーが出る
”Randomize seed”にチェックを入れると、”Error 'float’ object cannot be interpreted as an integer”というエラーが出てしまいます。
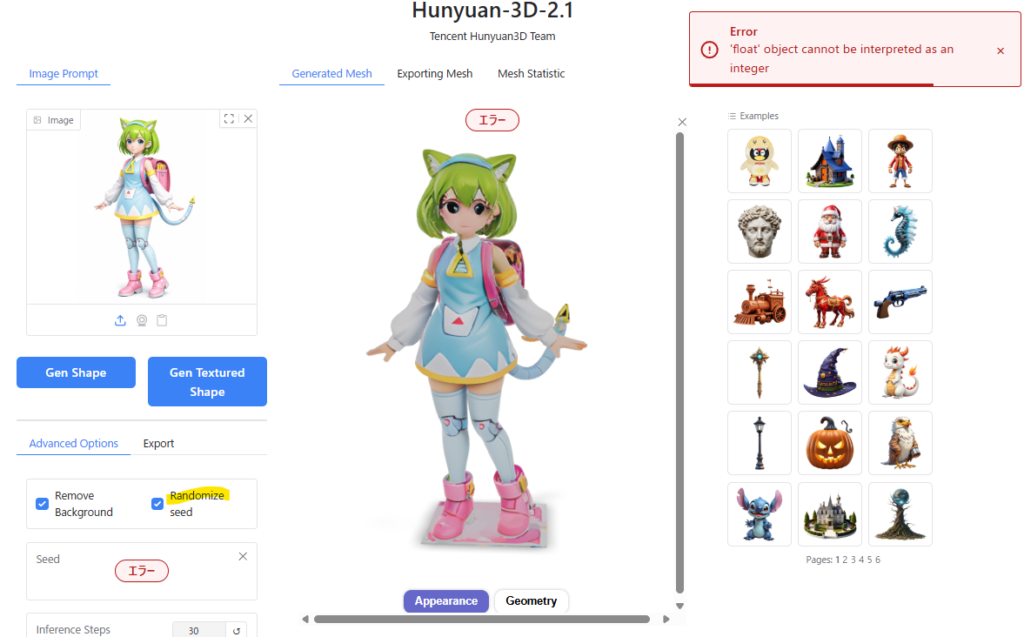
おそらく、Seedの値を渡す時に、整数(Int)ではなく浮動小数点(Float)として渡されてしまっているバグだと思います。
私は特に困っていないのでそのままにしていますが、元コードを直せる人は直してみてください。
設定による出力結果の違い
Hunyuan3D-2.0と同様に、バージョン2.1についても各パラメータの数値を変えたときに、生成結果がどうなるか比較検証してみましたので、結果をざっとお見せします。
結論としてはバージョン2.0のときと同様で、基本的にデフォルト設定のままでよくて、ディテールの品質を上げたい場合にOctree Resolutionの値を大きくする(場合によってはSeed, Inference Steps, Guidance Scaleも調整)のがおすすめです。
ちなみに、バージョン2.1のInference stepのデフォルト値は30となっています。バージョン2.0のデフォルト値の5にすると出力結果がおかしくなるので注意が必要です。
Inference Steps
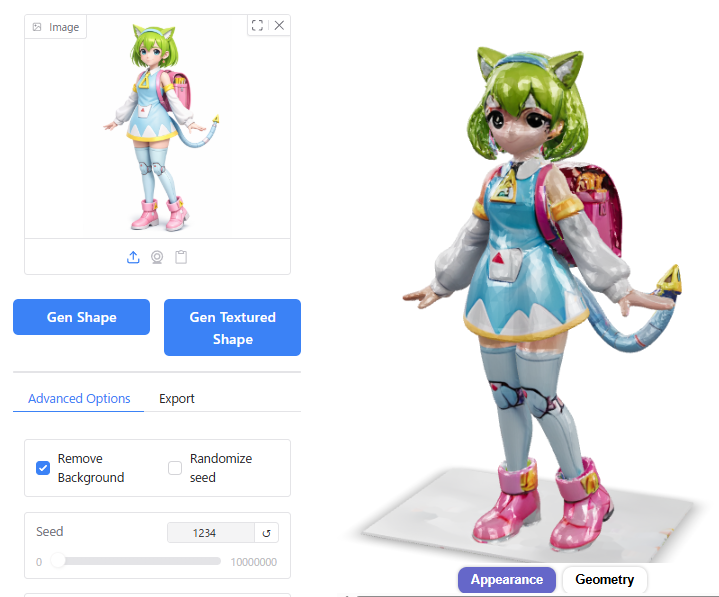
10以下だと形状が崩れてしまいました。
30より大きくしても、結果にあまり影響しませんでした。
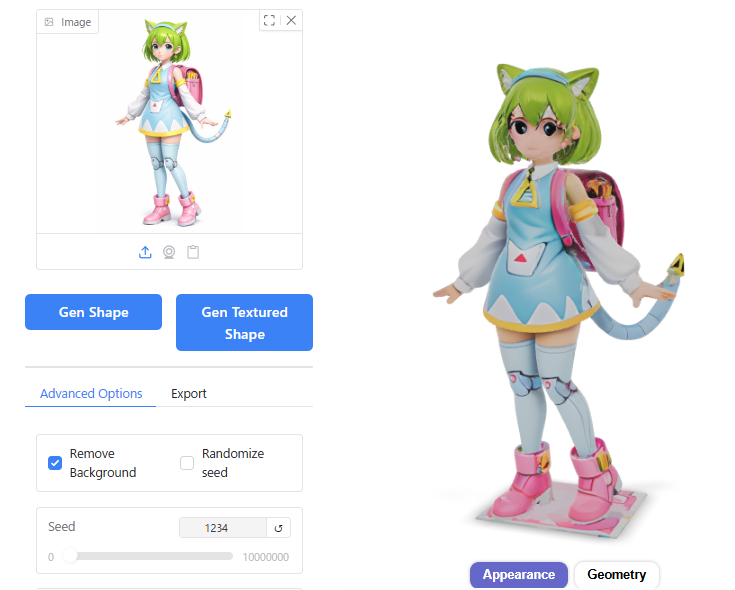
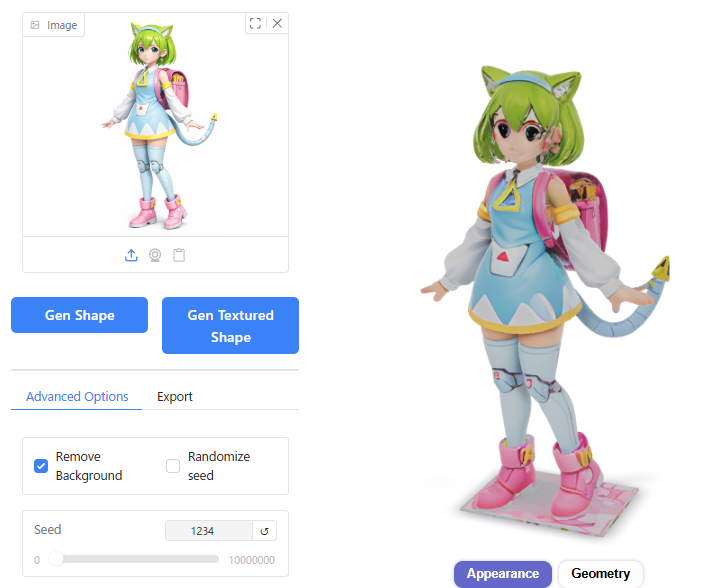
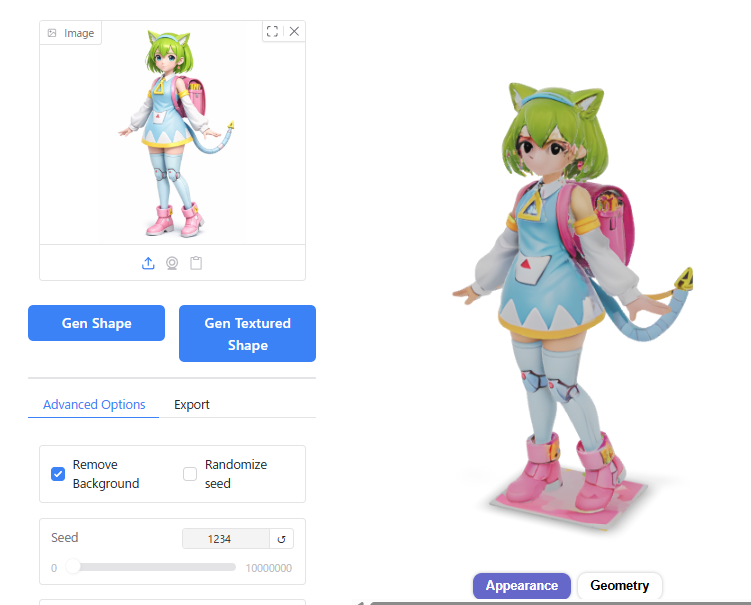
Octree Resolution
128だと顔などのディテールがやや省略されてしまいました。
256と512の差はあまりないように見えます。
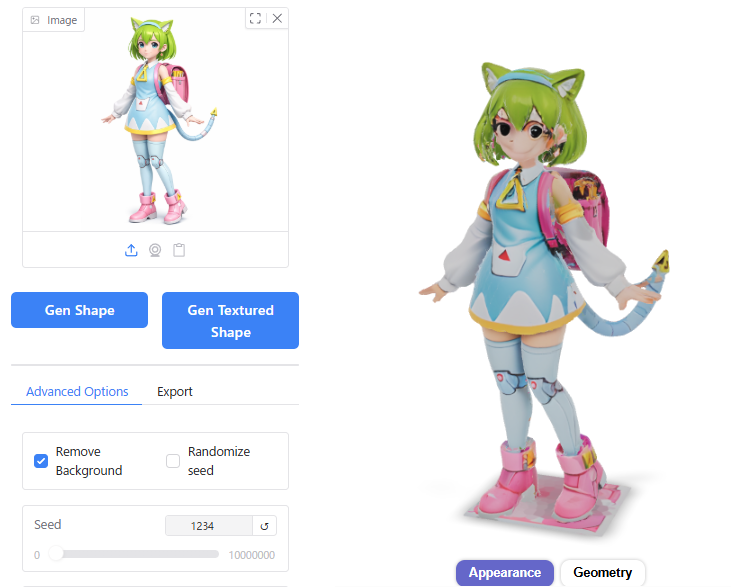
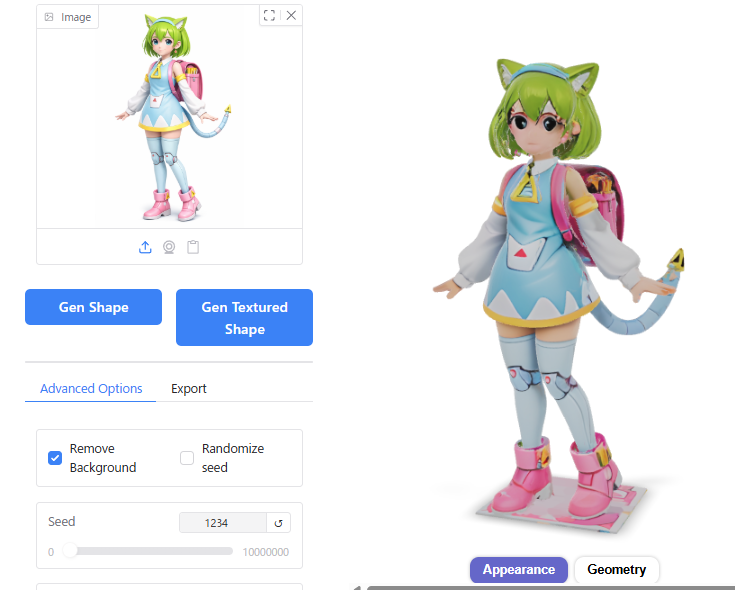
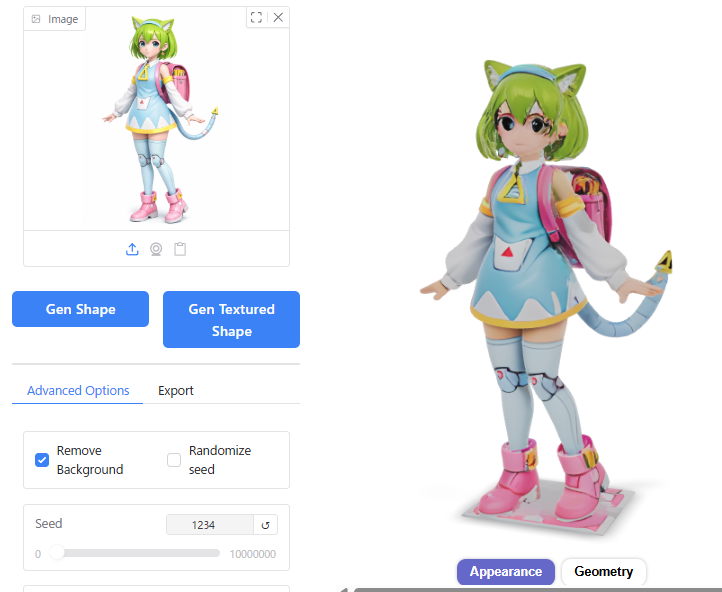
Guidance Scale
10よりも大きい値にすると、形状が破綻してしまいました。
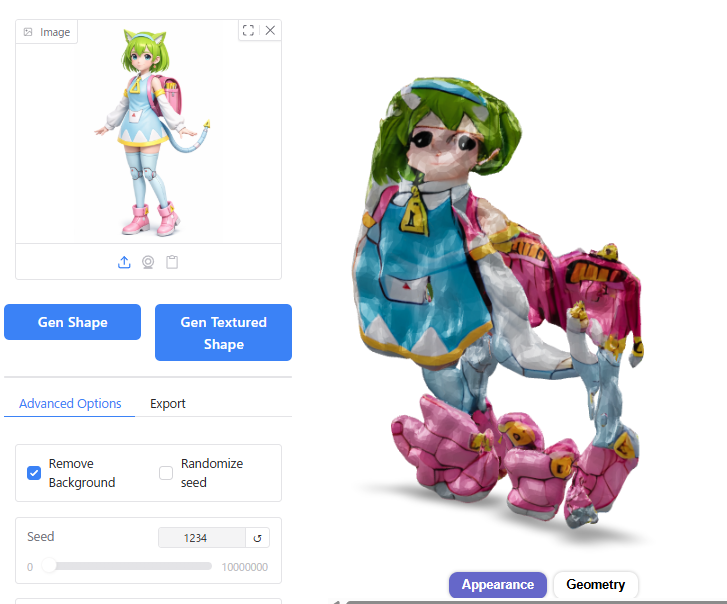
Hunyuan3Dを終了する方法
最後に、Hunyuan3Dを終了する方法を記します。
Hunyuan3Dを使用している際はLauncherとコマンドプロンプト、ブラウザの3つの画面が立ち上がっていると思いますが、終了する際はLauncherのウインドウを閉じます。
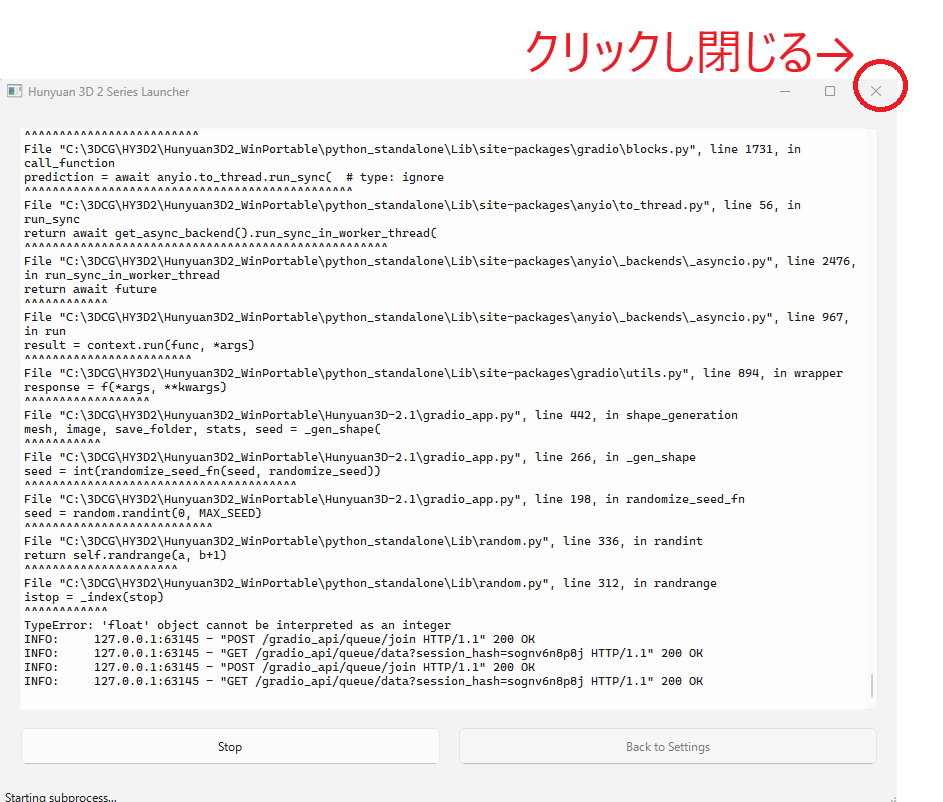
ブラウザを閉じても、Launcherが開いている間はHunyuan3Dは起動したままです(ブラウザを閉じると、生成したモデルはリセットされるので注意してください。)
Launcherを閉じると、開いているコマンドプロンプトも自動で閉じる。
Hunyuan3Dを終了する際の注意点
開いているコマンドプロンプトを、Launcherよりも先に閉じないよう注意してください。
コマンドプロンプトを先に閉じると、Hunyuan3Dが正常に終了されず、Hunyuan3Dを再度立ち上げた際にポート8080が使用中のエラーが出てしまうことがあります。
[Errno 10048] error while attempting to bind on address ('0.0.0.0', 8080)上記のエラーが出た場合は、Windowsのプログラムからコマンドプロンプトを立ち上げ、以下のコマンドを入力してみてください。
netstat -ano | findstr :8080このような表示が出た場合は、ポート8080がPID(プログラムID)12345によって占有されている状態です。
TCP 0.0.0.0:8080 ... LISTENING 12345以下コマンドを入力し、そのPIDを終了すればエラーは解消されます。
taskkill /PID 12345 /F広告/AD
まとめ
Hunyuan3D-2の導入と使い方について、一通り紹介してみました。
今回の記事が、自作PC愛好家の方にとって「PCを組んだ後に何に使うか」の選択肢を与えるきっかけになれば嬉しいです。
また、3DCGをされている方々に対しても、今後のAIを利用した作品制作の参考となればよいと思います(著作権の観点から、あくまでも下絵やリファレンス等としての使用が前提ですが)。
なお、今回の記事執筆でAIによる3D生成をわかりやすく・親しみやすくお伝えするため、BlendAI株式会社のキャラクター「デルタもん」を使わせていただきましたので、最後にあらためて感謝申し上げます。
広告/AD